What witness.ai Doesn't See
Your security team asked the right question. They evaluated witness.ai, ran the proof of concept, reviewed the architecture, and signed off. The network proxy is running. The shadow AI dashboard is live. The prompt injection firewall is blocking attempts in real time.
Everything you asked for is deployed.
Here is what nobody asked: where does the proxy stop? Because in a Claude Code environment, the proxy is not the last line of defense; it is not even close to all the lines. The most dangerous attack surface your engineers have created is operating entirely outside witness.ai’s visibility envelope.
That is not a product failure. It is a category mismatch.
What witness.ai Actually Does
Let me be precise before I critique, because imprecision in security discussions creates its own risks.
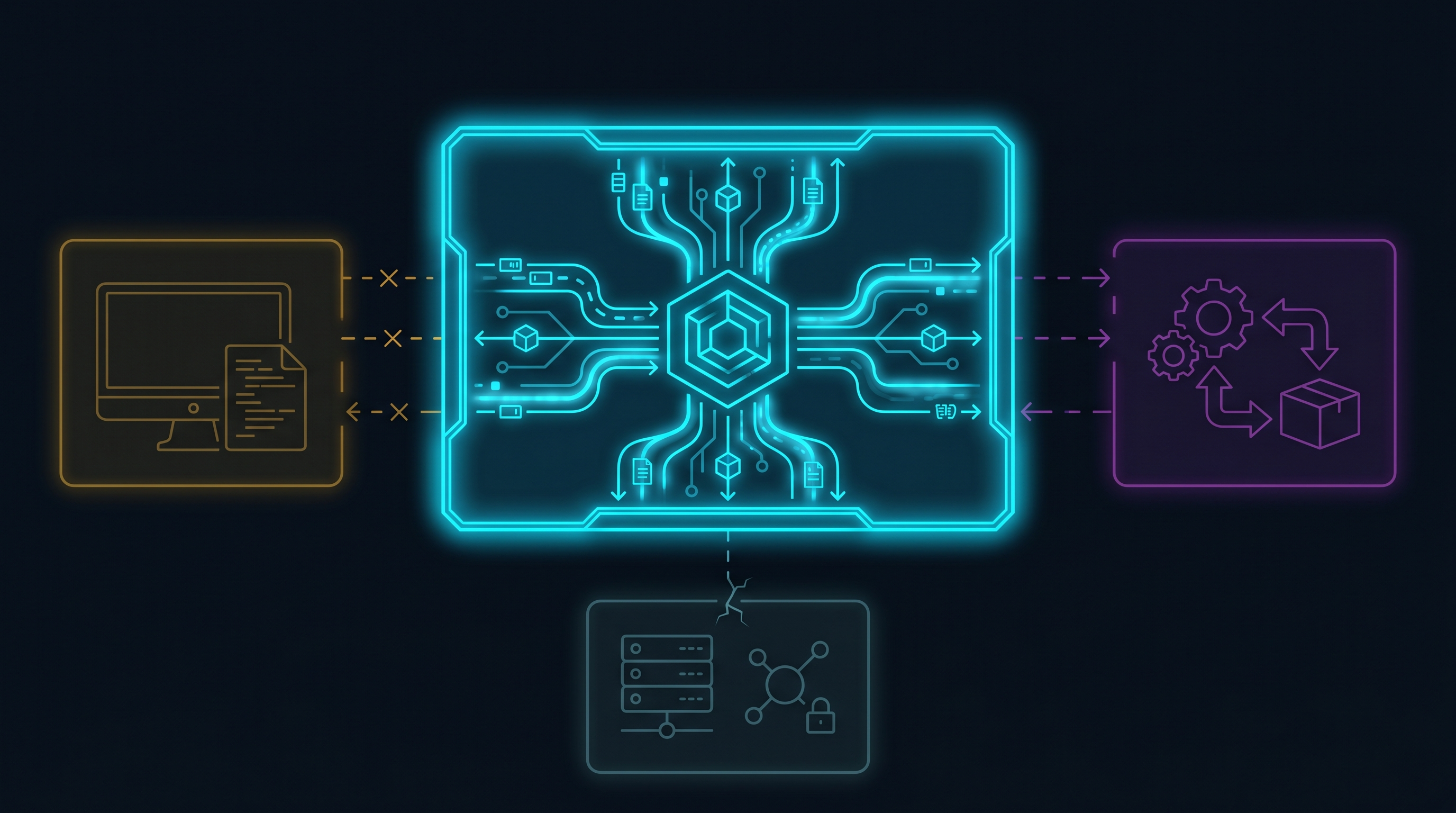
witness.ai, which raised $58M in January 2026 and added Agentic Security to its platform that same month, does real things well. Its core capability is network-layer visibility into AI activity across an enterprise. No endpoint agents required. The proxy sits in the data path, observing every conversation, prompt, and response that flows through it.
The shadow AI discovery capability is genuinely useful. Most organizations do not know which AI tools their engineers are actually using. witness.ai surfaces that inventory: which models, which tools, what frequency, what data classifications are flowing through. For a security team trying to understand its exposure surface, that is the first necessary step.
The AI Firewall is real. witness.ai claims more than 99% true-positive detection on prompt injection attempts at the conversation layer. I will caveat that number later, but the capability is legitimate and deployed in production at enterprises. PII and credential redaction in transit (tokenizing sensitive data before it reaches the model) is a meaningful control for conversation-based AI governance.
The Agentic Security addition from January 2026 extends coverage to Claude Desktop, ChatGPT plugins, VSCode AI extensions, and local agents running on developer machines (LangChain, LlamaIndex, CrewAI). MCP server fingerprinting maps which servers agents connect to. Intent analysis classifies whether agent outputs look anomalous.
This is not a minimum viable product. It is a legitimately useful enterprise AI governance platform.
The problem is not what witness.ai does. It is the threat model it was designed to address.
The Network Layer Is the Wrong Abstraction for Claude Code
Claude Code is not a chat interface. It is an execution environment.
When you use Claude Code, you are not sending messages to a model and reading responses. You are running an autonomous agent with file system access, bash execution, git operations, and extensible tool execution, operating on your developer machine and, increasingly, in your CI/CD pipelines.
The risks that matter in this model do not all flow through HTTP to api.anthropic.com. Some of them resolve before a single network packet leaves the machine. Others happen inside isolated containers that your enterprise proxy never reaches. Others live in the instruction content of MCP skills, invisible to any traffic inspection layer because the malicious payload is already inside the agent’s context by the time a request is made.
The engineer I wrote about in when-your-team-starts-building was already running Claude Code inside GitHub Actions in production, automating pull request reviews against team standards, in real repositories, with real credentials. That specific pattern is structurally invisible to witness.ai. Not because witness.ai is poorly built, but because the network proxy does not reach inside GitHub’s CI containers.
This is a threat model problem, not a product quality problem. witness.ai was designed to govern AI conversations at the network boundary. Claude Code’s attack surface extends below that boundary. Understanding where one ends and the other begins is the security posture question your team probably has not answered yet.
Here are the specific gaps.
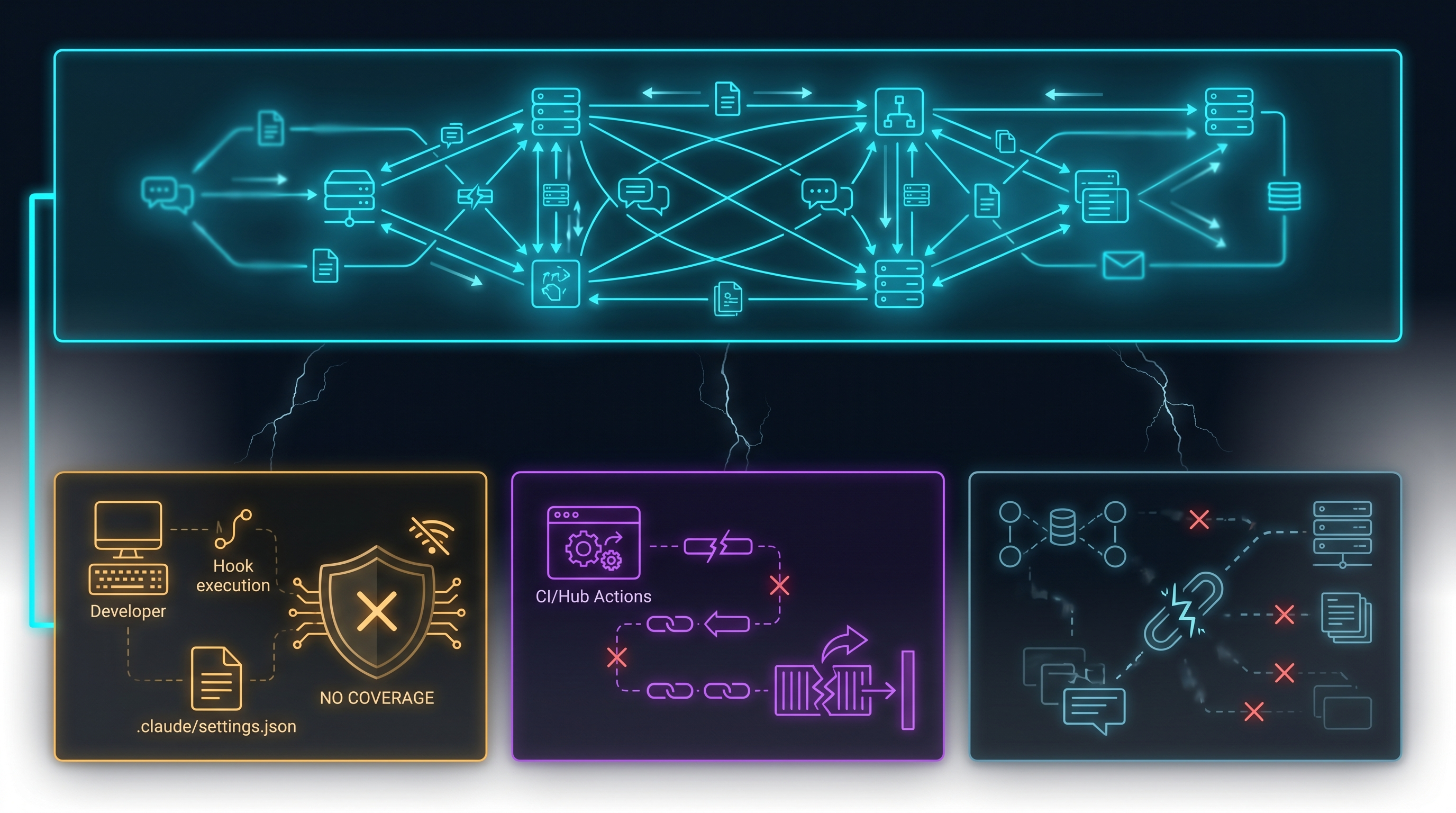
Gap 1: The Hook System
Claude Code’s project configuration system includes a feature called Hooks: arbitrary shell commands defined in .claude/settings.json that execute when Claude Code starts in a given directory. The use case is legitimate: pre-load context, run setup scripts, initialize environment variables. The attack surface is exactly what it sounds like.
Check Point Research documented three separate CVEs (CVE-2025-59536, with related vulnerabilities in .mcp.json and environment variable handling) demonstrating RCE and API token exfiltration through Claude Code project configuration files. The attack vector: a malicious repository ships a .claude/settings.json with hooks that execute before any network activity occurs. Clone the repo, run claude in that directory, and the hook fires. API keys exfiltrated. Shell commands executed. All before witness.ai’s proxy processes a single byte.
witness.ai coverage here: zero.
This is not a theoretical attack vector. It is a documented, reproducible vulnerability with assigned CVEs. And the fix is not on witness.ai’s side. It is on yours.
Treat .claude/settings.json the way you treat a Dockerfile or a GitHub Actions workflow: as a privileged execution manifest that requires code review, not a configuration file that developers self-approve. Practical controls beyond that:
- Include
.claude/settings.jsonin required review for all repositories where Claude Code is in use - Restrict which directories developers can open in Claude Code on managed machines
- Audit existing repos for Hooks that were never explicitly reviewed
- Consider Checkmarx’s Claude Code security framework for the full controls picture: permissions, sandboxing, and isolation are all relevant here
The gap exists because Claude Code’s permission model was designed for trusted developer machines. Your security posture needs to account for untrusted repositories landing in that environment.
Gap 2: GitHub Actions CI/CD Isolation
The GitHub Actions supply chain compromise in March 2025 put CI/CD secrets at risk in more than 23,000 repositories. That incident did not involve AI at all. Add autonomous AI agents to that attack surface and the blast radius changes significantly.
StepSecurity’s research on AI agents in GitHub Actions documents how agents running in CI can be manipulated via prompt injection to steal secrets, execute malicious code, or modify build artifacts, all while operating in isolated containers with restricted network egress.
That word “isolated” is load-bearing for witness.ai’s threat model. When Claude Code runs inside a GitHub Actions workflow, it operates in a container whose network egress goes through GitHub’s infrastructure, not through your enterprise proxy. The design intent is correct: containers should have restricted, audited egress. The security consequence is that witness.ai’s proxy is not in that path.
A prompt injection attack on a Claude Code GitHub Actions run (injecting malicious instructions via a PR description, a code comment, or an external data source the agent reads during execution) would succeed or fail based on Claude Code’s own defenses and your Actions configuration, not witness.ai’s firewall.
witness.ai coverage here: structurally none for agents executing inside Actions containers.
The architecture that actually addresses this:
- GitHub’s Agentic Workflows security architecture includes dedicated containers, restricted egress, and vetting gates; use those, do not build around them
- StepSecurity Harden-Runner restricts outbound egress from Actions runners to a known allowlist, significantly constraining the blast radius of a successful injection attack
- Require explicit human approval gates before Claude Code Actions can modify production-facing resources
- Treat every external data source an Actions agent reads as potentially adversarial input
This is the pattern your team needs to audit right now. Not because witness.ai failed, but because the CI/CD AI governance question never made it into the evaluation criteria.
Gap 3: MCP Skill Supply Chain
Claude Code’s extensibility model runs through Model Context Protocol: servers that expose tools, resources, and prompt instructions to the model. An MCP server can be an internal knowledge base, a code search tool, an API wrapper, or anything else you can package into the protocol.
It can also ship malicious instructions inside the skill’s markdown definition: instructions that get injected into the model’s context before the model generates any response. witness.ai can see that an MCP server was connected. It cannot inspect the instruction content of that server’s skills before execution.
Snyk’s ToxicSkills audit is worth reading carefully if you run Claude Code in your organization. Of 3,984 skills scanned, 1,467 contained malicious payloads, 36% of all skills. Of the confirmed malicious skills, 91% combined prompt injection with traditional malware, specifically designed to bypass both AI safety mechanisms and conventional security tools simultaneously. The attack does not require a developer to install an obviously malicious tool. It requires them to install a legitimate-looking MCP server that happens to include instructions telling the model to do something your security team would not approve of.
witness.ai’s MCP server fingerprinting maps connections and classifies intent. That is useful for auditing what is installed. It does not address what those servers instruct the model to do.
Controls that actually address this:
- Org-internal MCP server registry: engineers connect Claude Code only to servers that have passed a security review
- No public MCP servers in production Claude Code contexts, full stop
- Treat the skill definition content of any external MCP as adversarial until proven otherwise
- Add MCP server auditing to your application security review process: this is an AppSec problem, not just an AI governance problem
This gap exists across every AI governance tool in the market today. The OWASP Agentic Applications Top 10 (2026) identifies malicious skills as the top attack vector for agent security precisely because no vendor has solved static analysis of skill instruction content yet.
Gap 4: Configuration Layer Hijacking
This one is more surgical but worth naming because it is the kind of attack that bypasses every network-level control by design.
ANTHROPIC_BASE_URL is an environment variable (also settable in .claude/settings.json) that redirects all Claude Code API traffic to an arbitrary endpoint before the request reaches Anthropic. A malicious project configuration sets this variable to an attacker-controlled proxy. The API traffic flows through that proxy first, capturing API keys and model inputs, then forwards to Anthropic normally. The developer notices nothing. witness.ai sees legitimate traffic to api.anthropic.com from the enterprise network; the interception already happened upstream.
CVE-2026-21852 documents this attack vector specifically.
witness.ai coverage: none. The interception happens at the OS and config layer before any network egress the proxy can see.
Microsoft’s May 2026 research on misconfigurations in AI applications frames this well: configuration files are the new attack surface for AI-assisted development tooling. The perimeter is the developer’s local environment, not the network edge. Monitoring and alerting on ANTHROPIC_BASE_URL being set anywhere in your developer environment is the minimum viable control here.
Gap 5: The >99% Claim in Context
witness.ai claims more than 99% true-positive detection on prompt injection. That claim deserves scrutiny before your security team treats it as a hard guarantee.
The practical problem is injection through trusted data. When a developer asks Claude Code to review a PR that contains a carefully crafted comment designed to manipulate Claude’s behavior, that comment arrives as code, trusted data from a colleague, not as an adversarial message. The firewall classifies content based on context and pattern. A sufficiently sophisticated injection embedded in plausible-looking code, documentation, or ticket content is harder to classify than a direct jailbreak attempt.
Systematic research on prompt injection attacks against agentic coding assistants consistently shows that adaptive attacks (attacks designed with knowledge of the defender’s architecture) achieve meaningfully different results than the unsophisticated attempts that make up the bulk of production traffic.
Microsoft’s Semantic Kernel CVEs from May 2026 (CVE-2026-25592 and CVE-2026-26030) are the concrete proof point: prompt injection that achieves host-level RCE by exploiting the gap between what a safety system classifies as dangerous and what the underlying execution environment actually allows. The injection does not look dangerous at the message layer. The damage happens at the execution layer.
The honest framing: witness.ai’s detection capability significantly raises the cost of unsophisticated attacks. It is not an impenetrable barrier against a motivated adversary who understands the detection architecture. Apply it where it adds value. Do not treat it as your last line of defense.
What Defense-in-Depth Actually Looks Like
The answer is not “do not use witness.ai.” The answer is to use it for what it is actually good at, and layer controls that address the gaps it cannot reach.
witness.ai stays: It is the right tool for shadow AI discovery, conversation-level governance, and MCP server mapping. Know the coverage boundary. Your security team should be able to draw that line on a whiteboard before signing off on any AI governance posture.
GitHub Advanced Security: Secret scanning on every repository that contains Claude Code configuration files. Push protection to catch credentials before they are committed. Code scanning to catch the broader vulnerability class that Claude Code might introduce or miss.
Microsoft Defender for DevOps: This is the CI/CD visibility layer that witness.ai does not provide. Native GitHub and Azure DevOps integration surfaces security findings from pipeline executions that a network proxy cannot reach.
StepSecurity Harden-Runner: Restrict outbound egress from GitHub Actions runners to a known allowlist. This does not eliminate AI agent risk in CI/CD but significantly constrains the blast radius of a successful injection attack.
Internal MCP registry: No external MCP servers in production Claude Code contexts without a security review gate. This is a policy control, not a technical one, but it addresses the ToxicSkills attack vector more directly than any governance tool currently on the market.
Config auditing: Include .claude/settings.json, .mcp.json, and any Hook definitions in mandatory code review. These files are privileged execution manifests. Treat them accordingly.
The structural pattern I described in the agent identity federation gap post applies here exactly: you cannot govern what your tooling cannot see. Knowing your coverage boundary is not a weakness. Not knowing it is.
Honest Admission
witness.ai is moving quickly. Agentic Security launched in January 2026; the product is actively expanding its coverage model. Some of the gaps I have described may narrow. The hook system and CI/CD isolation gaps require architectural cooperation from Anthropic and GitHub respectively; those are not unilateral fixes witness.ai can ship. The MCP vetting gap is theoretically addressable in product.
I am also working from public documentation and security research. I do not have visibility into witness.ai’s full roadmap or what enterprise-tier capabilities exist beyond public documentation.
What I am confident about: these gaps exist in the current state. Your security team should map them before treating witness.ai as comprehensive Claude Code coverage. The fact that a vendor is moving fast does not change what the product covers today.
Know the Boundary Before You Sign Off
Your security team did not ask the wrong question. The honest answer to “does witness.ai cover us?” is: it covers the conversation layer, and the conversation layer matters. It does not cover the configuration layer, the CI/CD isolation layer, or the MCP supply chain layer in your Claude Code environment.
Those gaps require different tools, different policies, and a different mental model than the network proxy model witness.ai operates in.
The engineers at your organization are building with Claude Code right now. Some of them are already running it inside GitHub Actions. The attack surface they are creating is real, documented, and exploitable. Knowing where your current coverage ends is how you decide where to build next.
The compliance evaluation framework in Your AI Toolkit is Probably Illegal assumed the tool you’re governing talks to the network. Claude Code changed that assumption. If you’re working through AI security posture in a regulated environment, I’m building this out in public. Find me at @orestesgarcia on X or LinkedIn.