The Zero-Copy Promise
You connected your ETL pipeline to the Snowflake share and things got worse. That’s not a Snowflake problem.
How We Got Here
Let me describe something that happens a lot in banking data shops right now.
You had a pipeline that worked, barely. Your core banking provider dropped a flat file every night at 2am. Your pipeline picked it up at 3am, ran the transforms, loaded into the warehouse. By 6am your risk and finance teams had their dashboards. Painful, but it made the SLA.
Then came the upgrade. The vendor migrated to a Snowflake-native data share. No more flat files. The share is cleaner, richer, real-time. This is better, they said.
So you did what any reasonable team does: you updated your pipeline to point at the Snowflake share instead of the SFTP drop. Same pipeline, new source. Reasonable adaptation.
The share takes until 4am to provision and make available. Your pipeline kicks off at 4:30am. The warehouse refreshes by 8am, two hours past your SLA. Your users are angry. Your team is confused. The vendor’s product is objectively better than the old flat file. But things got worse.
The question (what did I gain?) is exactly right. The honest answer: nothing. Because you changed the source without changing the architecture.
What the Share Is Actually For
A Snowflake data share is not a better flat file. It’s a live query endpoint.
When your core banking provider gives you a Snowflake share, they’re exposing a database object in their Snowflake account that your Snowflake account can query directly: no data movement, no export, no transfer. The data lives in their storage. Your query crosses a metadata boundary and reads it in place.
Snowflake’s data sharing architecture is built on this principle: the provider shares access to objects, not copies of data. The consumer gets a live view, updated the moment the provider’s data changes. No egress charges, no provisioning windows, no refresh lag.
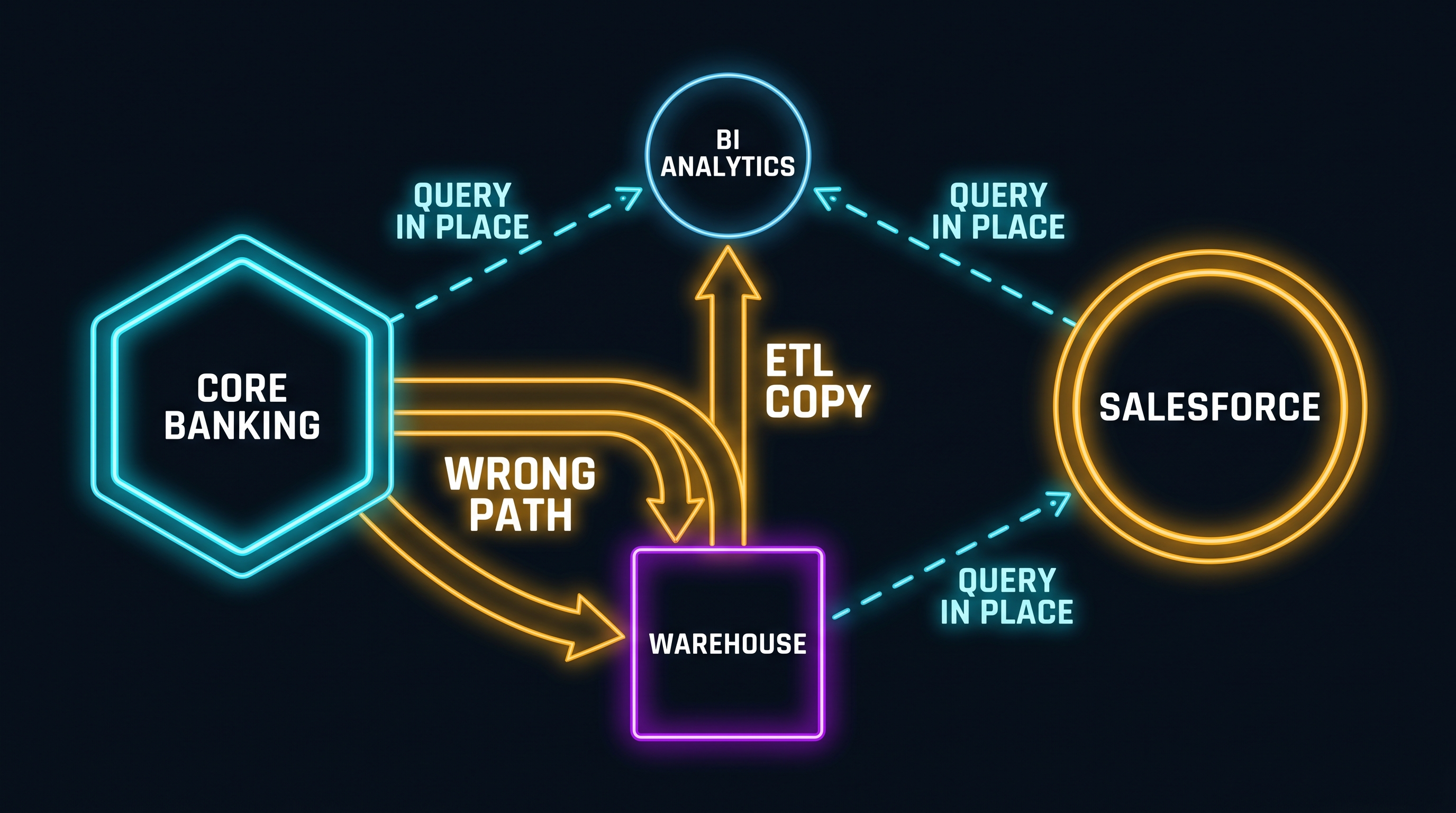
The value only appears when you stop using the share as an ingestion source and start using it as a query target.
Instead of: wait for share → run pipeline → warehouse refresh → query. It becomes: query the share directly when you need the data.
This is the same shift I described in Open at the Bottom, Locked at the Top: the platform value isn’t in better data movement, it’s in eliminating data movement as the default. Microsoft Fabric’s OneLake operates on the same principle: shared storage, separate compute engines, no copies required.
But You Can’t Query Everything In Place
Here’s where the real dilemma starts.
Read-only queries on your core banking share work fine. Your executive dashboard showing current deposit balances, transaction volumes, and product counts can query the share directly, get live data, never miss a refresh window again.
But that’s not what most of your warehouse is doing.
Your regulatory reporting joins core banking data with your GL system, your Salesforce CRM, and your risk models. Your PII-sensitive datasets get masked before they’re exposed to downstream consumers. Your audit reports need immutable point-in-time snapshots certifiable as of a specific timestamp. Your compliance team needs data that won’t return different results two minutes apart.
None of that is possible on a share you don’t own. You can’t run transformations on the provider’s data. You can’t join it against other sources in a single atomic transaction. You can’t apply a compliance schema to data the provider didn’t design for it.
The Snowflake share gives you the raw core banking view of your customers. Your warehouse gives you the joined, governed, transformed enterprise view. They’re different things. The mistake is treating them as interchangeable.

The Decision Framework: Copy or Reference?
Every dataset your warehouse currently ingests needs to answer one question: Does this use case require the warehouse to add something: a join, a transform, a rule?
If yes, copy it. If no, query it in place.
Reference in place (query the share directly) when:
- Read-only analytics. Account balances, transaction counts, product holdings where the raw source view is what you need
- Regulatory data residency. Data that must remain in the provider’s environment under your governance agreement
- Freshness beats consistency. When live data is worth more than a point-in-time snapshot
- Source availability matches your SLA. When your analytics can tolerate the provider’s availability model
Copy it (ETL/ELT into your warehouse) when:
- Cross-domain joins required. Combining core banking with Salesforce CRM, GL, risk engines, or compliance systems
- Transformation required. PII masking, regulatory calculations, business rule application that can’t run on the provider’s side
- Audit trail required. Compliance needs an immutable record as of a specific timestamp
- Availability guarantee required. Downstream consumers need data regardless of provider share status
- Query economics. At very large scale, federated queries can cost more in compute than copying the data once
The enrichment middle ground:
Some data can be enriched at query time without copying the base dataset. Join the provider share live against a small reference table you maintain in your warehouse: customer segment classifications, product category mappings, regional hierarchies. The source data never moves. The enrichment happens at query time.
This pattern is underused. It’s how you get zero-copy for the heavy source data while still adding the business context that makes it useful. The same logic applies to identity resolution: augmenting authoritative source data at query time instead of copying it. I covered that version in Same Person, Five Systems, where the golden-record problem in banking turns out to be an enrichment problem more than a storage problem.
Salesforce Data Cloud 360: Same Dilemma, Different Axis
Salesforce’s version of this is the Zero Copy Partner Network, and it runs bidirectionally.
Your warehouse can query Salesforce Data Cloud insights directly (customer segments, campaign membership, engagement scores) without ingesting them. Salesforce flows can query your warehouse directly for account balances and product holdings without pulling them into Salesforce storage. No copy in either direction.
The same trap applies. If you ingest Salesforce Data Cloud into your warehouse via an ETL pipeline, you haven’t adopted zero-copy; you’ve built a slower Salesforce export with extra steps.
The value appears when your BI layer queries Salesforce directly for campaign analytics instead of waiting for an overnight sync, and Salesforce flows query your warehouse directly for real-time account data instead of relying on a CRM refresh job.
But: Salesforce data you need to join with core banking data in a single query still needs to land somewhere. You can’t join two live external shares in real time and produce a deterministic, auditable result. That cross-source join is still a warehouse job. The warehouse’s role isn’t to hold everything; it’s to be the join layer for data that genuinely requires joining.
What Your Refresh Window Is Actually Telling You
When your daily refresh window starts failing, the instinct is to look at the pipeline. Tune the query. Add more workers. Optimize the source connection.
That’s the wrong frame.
A refresh window under pressure is an architecture signal. It’s telling you that something you’re copying probably shouldn’t be copied, or shouldn’t be copied as often. For every pipeline that’s struggling, ask: is the warehouse adding transformation value here, or just providing proximity?
Proximity, having the data “nearby” in your own warehouse, used to justify copying everything. In an on-premises world, it made sense. In a cloud-native stack where Snowflake shares cross account boundaries at zero egress cost, proximity is no longer a reason to move data.
The pipeline doing the least work (pull, stage, load, no transforms, no enrichment) is the most wrong. That’s where zero-copy pays off first. Not in your complex regulatory reporting pipeline that genuinely needs to transform and govern the data. In the read-only feed you’ve been running as an ETL job for fifteen years because that’s just how data pipelines worked.
Data Topologist, Not Pipeline Builder
The title shift matters more than it sounds.
Pipeline builders build pipelines. When a new data source appears, they build a pipeline. When a share appears, they build a pipeline pointed at the share. That’s the instinct that made things worse.
Data topologists ask a different question: where does this data live, who owns it, and does it actually need to move?
The topology question forces you to map your data landscape by ownership. What lives in the core banking Snowflake share. What lives in Salesforce Data Cloud. What lives in your warehouse because it’s genuinely a product of transformation work your warehouse performs. You draw the boundaries explicitly instead of defaulting to “everything gets ingested.”
Your warehouse shrinks to what it should always have been: the layer where cross-domain joins and business transformations happen. Not the universal data sink. Not the single source of truth for data you don’t own and don’t transform.
Governance migrates with it. Instead of managing pipeline DAGs, you’re managing share permissions, data contracts with external providers, catalog policies that describe what can be queried where. It’s a different kind of complexity, one that matches the actual structure of your data landscape rather than fighting it by forcing everything into one place.
The Honest Part
Zero-copy shifts complexity. It doesn’t eliminate it.
When your dashboards query the provider share directly, the provider’s uptime is your SLA. When their Snowflake environment is degraded, your dashboards are degraded. You’ve traded pipeline SLA risk for source SLA risk. That’s a real trade-off your reliability team needs to understand explicitly before it shows up in a production incident.
Federated query compute at scale can cost more than the storage savings from eliminating copies. Joining two massive external shares in a distributed query is expensive. Measure before you commit to the pattern for large datasets.
Catalog governance is harder than it looks. Managing share permissions across dev, test, and production environments, tracking which consumer accounts have access to which provider objects, is not yet a fully solved operational problem. Data contracts with external providers don’t have the same maturity as internal pipeline contracts.
But the alternative (a warehouse trying to ingest and refresh everything on a schedule it can no longer make) is already failing. The direction is set. The question is whether you make the transition deliberately or keep patching the ETL.
The Question to Carry Into Your Next Architecture Review
The flat file is going away regardless. Snowflake shares are how modern core banking vendors will offer data access. Salesforce Data Cloud is a real and growing layer of enterprise analytics infrastructure. This shift is not optional.
For every dataset currently in your warehouse, ask: did it move because it had to, or because moving everything was the only architecture you had?
The refresh window that’s failing is the clearest possible answer.
The platform economics of this shift, how lock-in migrates when the format layer opens up, is the subject of Open at the Bottom, Locked at the Top. The identity dimension of managing the same customer across five source systems is in Same Person, Five Systems.
I’m at @orestesgarcia on X and LinkedIn if you’re working through a similar architecture decision, or if the 8am dashboard story hit a bit too close to home.