
Open at the Bottom, Locked at the Top: The Real Story of Microsoft Fabric
Microsoft announced Fabric with Delta Lake, Parquet, and open table formats. The message was hard to miss: we’re not locking you in. That message is technically accurate. It is also strategically incomplete. The lock-in didn’t disappear — it moved.
This distinction matters. Not because Fabric is a bad platform. But because “open formats” is doing a specific rhetorical job in the sales motion, and if you don’t understand what it is and isn’t promising, you’ll make architecture decisions you’ll spend years unwinding.
What “Open” Is Actually Buying You
Every enterprise evaluation I’ve watched go through a Fabric decision eventually surfaces the same question: what happens if we want to leave? And the answer the field gives — Delta Lake, Parquet, open formats, shortcuts to S3, Iceberg interoperability with Snowflake — is accurate as far as it goes.
Your data is genuinely readable from the outside. Databricks can point at your OneLake storage and read your Delta tables. Snowflake can mount your Parquet files. Open-source Spark, DuckDB, Trino — anything that speaks Delta works. The format story is real.
But there’s a question underneath that question that rarely gets asked: can you replicate the experience?
This is the same issue I explored in the context of AI infrastructure. In The AI Context Portability Problem, I wrote about how the raw data — the files, the context — is usually portable. The intelligence accumulated on top of that data is what gets stranded. Fabric has the same structure, and it’s not accidental.
What “Open at the Bottom” Actually Means
Let’s be specific about what’s genuinely open in Fabric, because the list is real and the commitment is meaningful.
OneLake — exactly one per tenant — sits on Azure Data Lake Storage Gen2 and stores all tabular data as Delta Lake. Delta is open-source. The Parquet files plus the transaction log are readable by anything. There’s no proprietary wire format, no opaque binary store. A Delta table written by a Spark notebook in Fabric looks exactly like a Delta table written by Databricks.
Shortcuts extend this further. You can mount Amazon S3, Google Cloud Storage, and other ADLS Gen2 storage directly into OneLake without moving the data. Your S3 bucket appears as a folder — readable by every Fabric workload. Microsoft has also added Iceberg interoperability, letting Fabric read and write Iceberg tables that Snowflake or Databricks also consume. The open-format perimeter is genuinely large.
This is not a trick. The commitment to Delta and Parquet across all six Fabric workloads — Data Engineering, Data Warehouse, Real-Time Intelligence, Data Science, Data Factory, Power BI — is architecturally real. When Microsoft says “one copy of data, zero duplication across workloads,” the mechanism is legitimate.
The question is what sits on top of it.
What “Proprietary at the Top” Actually Means
Here’s where the lock-in lives, and each mechanism is worth naming precisely.
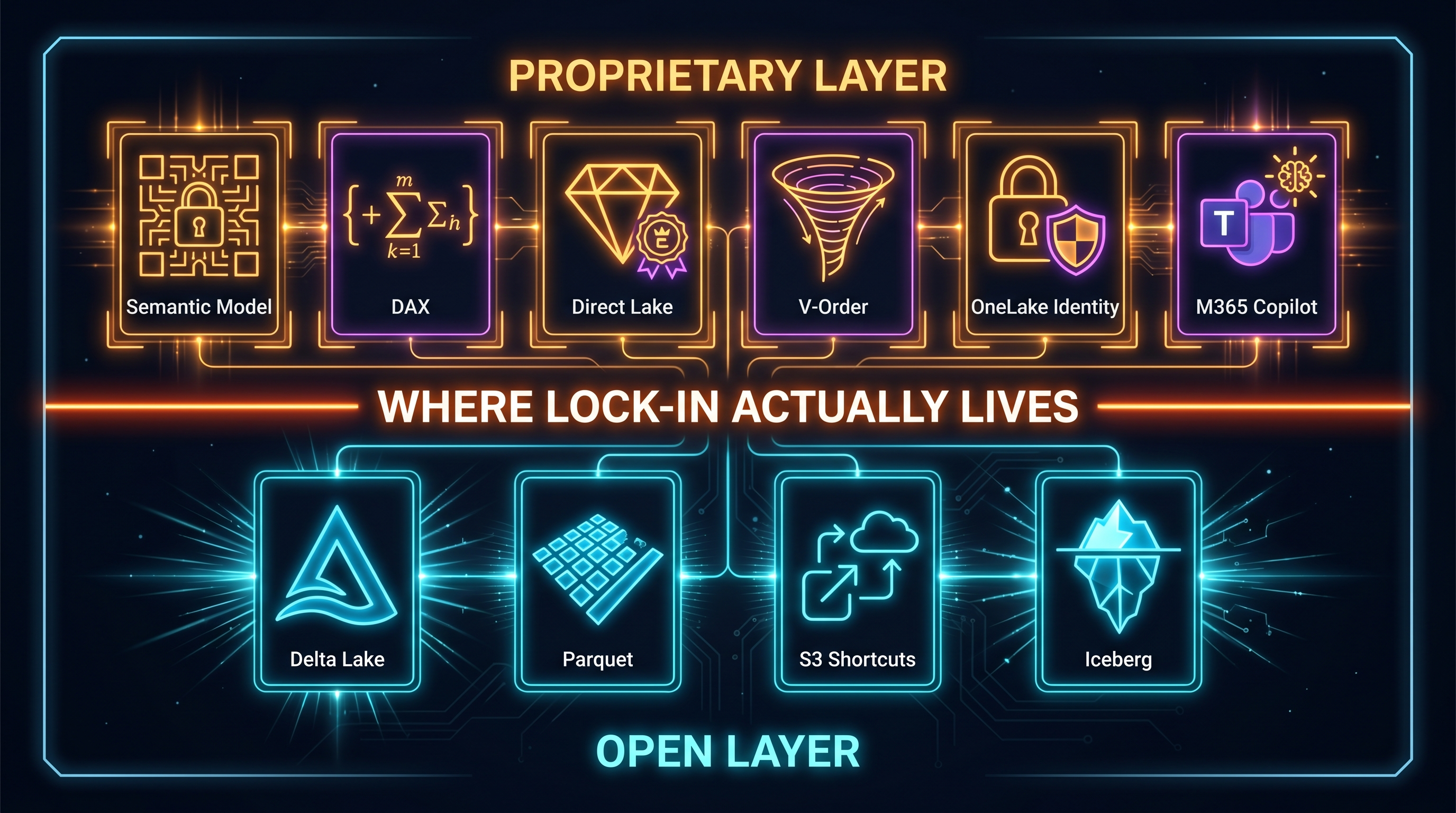
Semantic models and DAX. Power BI’s semantic model is where business logic lives. Measures, calculated columns, hierarchies, row-level security rules — all written in DAX, Microsoft’s proprietary formula language. These models are not portable. They don’t compile to SQL. They don’t export to dbt or LookML or any other open format. When practitioners talk about accumulated business logic being stranded, this is what they mean. The Parquet is portable. The analysis layer on top of it is not.
Direct Lake. This is Fabric’s headline Power BI feature, and it’s genuinely impressive. Power BI reads Delta Parquet directly from OneLake without importing the data or round-tripping queries through DirectQuery. The result is Import-speed performance with DirectQuery freshness. The catch: this mode is Power BI-exclusive. Tableau, Qlik, Looker, and every other BI tool falls back to DirectQuery, which carries a per-query latency tax and a one-million-row return limit. Switch your BI layer and you pay the DirectQuery penalty — or you rebuild your reporting stack on imported copies.
V-Order. This one is subtle and rarely surfaces in evaluations. When Fabric writes Parquet to OneLake, it applies V-Order — a proprietary Microsoft sort optimization that improves query performance for Power BI and the Fabric SQL engine. The files are still valid Parquet. Non-Microsoft engines can read them. They just read them slower, because V-Order’s compression benefits are tuned for Microsoft’s query engines. It’s the storage-layer equivalent of a proprietary index: the data is accessible, but the performance advantage is only available to the ecosystem that designed the format variant.
OneLake as identity boundary. Exiting Fabric means more than moving Parquet files. OneLake is governed through Entra ID. Workspace-level RBAC, row-level security on semantic models, column-level security on warehouses, sensitivity labels via Microsoft Purview — all of this is wired into Microsoft’s identity and governance stack. Rebuilding these controls in Databricks Unity Catalog or Snowflake’s governance model is not technically impossible. It is an architectural project, not a migration script.
M365 Copilot integration. This is the newest and deepest vector. Fabric Data Agents — published semantic models and AI Skills — are now callable from Microsoft Teams, M365 Copilot, and Copilot Studio. Business users can ask natural-language questions in Teams and get answers grounded in OneLake data. This integration path is Microsoft-exclusive. Databricks Genie and Snowflake Cortex Analyst don’t surface in Teams. The data substrate for enterprise AI agents is increasingly the platform where that integration is tightest — and right now, that’s Fabric’s corner of the stack.
Why This Is Strategy, Not Oversight
Microsoft has run this playbook before. The most instructive precedent is Azure on Linux.
Microsoft bet heavily on open-sourcing Linux kernel support, shipping Ubuntu and RHEL as first-class options on Azure, and making Azure the best cloud to run open-source Linux workloads. The message was “Microsoft loves Linux,” and it was accurate. It was also strategically motivated. Azure’s managed services — AKS, Azure Database, Azure Functions — are where the value extraction happens. Linux at the substrate; Azure’s experience layer on top.
I’ve written before about convergent evolution in platform strategy — how the same architectural attractors keep appearing independently across different domains. “Open at the storage layer, proprietary at the experience layer” is one of those attractors. It’s the answer to a real constraint: in a world of commoditized compute and storage, differentiation has to live somewhere above the commodity layer.
Open formats commoditize the substrate and push competition up-stack to catalog, governance, BI, and AI integration — exactly the layers where Microsoft has durable advantages that Databricks and Snowflake can’t easily replicate.
This is not a conspiracy. It’s a coherent strategy. Fabric is betting that once an organization has spent two years building semantic models, writing DAX measures, publishing Direct Lake reports, and wiring Data Agents into Teams, the exit cost isn’t “can I read the Parquet” — it’s “can I rebuild everything that made Parquet useful.”
The Real Exit Cost Calculation
When practitioners audit Fabric portability, the right frame isn’t “what can I take with me.” It’s “what do I have to rebuild if I leave.”
What’s genuinely portable: the Parquet files, the Delta transaction logs, the raw data in OneLake. If you leave Fabric, these follow you. You’re not stranded at the storage layer.
What isn’t portable: the semantic models and DAX measures that encode business logic. The Power BI reports built on Direct Lake assumptions. The workspace structure, RBAC policies, and sensitivity labels tied to Entra ID. The M365 Copilot and Teams integrations surfacing Fabric Data Agents to business users. The V-Order performance optimization that makes your queries fast on Microsoft engines.
This is the same governance gap I described in The Architect’s Dilemma — decisions made in one layer that create constraints in another without anyone explicitly choosing the dependency. You adopt Fabric for Power BI Direct Lake performance. You build semantic models because that’s how Power BI works. Those models accumulate business logic over time. That logic is now the asset, and it lives in a format that doesn’t travel.
The Honest Part
Every major platform does this. Databricks has Unity Catalog — a governance model that creates its own stickiness once you’ve organized your data assets around it. Snowflake’s Iceberg pivot is real, but Snowpark, Cortex functions, Native Apps, and Snowflake-specific SQL extensions are proprietary. BigQuery has its own storage format, its own ML functions, its own Looker integration. AWS Lake Formation governs things in ways that don’t map cleanly to other clouds.
The question isn’t whether lock-in exists. It does, everywhere, always. The question is whether you’re making the decision consciously — with full awareness of where the proprietary layer starts — or inheriting it by default because someone in procurement said “it integrates with our existing Microsoft licenses.”
Fabric is probably the right platform for a majority of Microsoft-heavy enterprises. The integration economics are real. The Power BI installed base makes Direct Lake a genuine productivity multiplier. I’m not arguing against Fabric. I’m arguing that “open formats” doesn’t mean “no lock-in.” It means the lock-in moved somewhere you can see clearly if you look at the right layer.
What to Watch as the Stack Deepens
The lock-in curve is still accelerating. Fabric’s Databases workload now includes SQL database and Cosmos DB as first-class Fabric items — transactional data entering the same gravity well as analytical data. Data Agents callable from M365 Copilot mean the experience layer is reaching business users directly in Teams. The Osmos acquisition brings agentic pipeline healing and self-repairing data workflows into the same stack.
Every semantic model you publish, every Data Agent you wire into Teams, every operational workflow you move into Fabric Pipelines deepens the experience-layer investment. The Parquet is portable at any of those stages. The experience built on top of it is not designed to travel.
Know what you’re building on. The storage is open. The rest of it isn’t.
This post is part of a running thread on platform strategy and vendor economics. If you’re thinking through a similar evaluation — or you think I’ve got the lock-in mechanics wrong — I’m at @orestesgarcia on X and LinkedIn.