The AI Context Portability Problem
I keep my AI setups separate. My work Claude Buddy—configured for company projects—stays in work contexts. My personal setup lives on my personal machine with its own configuration. The Layer 3/4 boundary I described earlier exists precisely to avoid mixing the two.
My personal setup came first. It’s where I’ve invested the most—months of refining workflows, tuning prompts, building skills, creating the signal feedback loops that make the AI better over time. That’s why I built Claude Buddy in the first place: to have infrastructure I control, that learns how I work, that stays with me regardless of where I’m employed.
But here’s the thing: even with that foundation, work context accumulates. The AI absorbs the codebase’s architectural patterns. It learns which approaches have failed and why. It encodes hard-won lessons about this specific environment into how it responds. Some setups can even write their own skills based on what they learn—the AI improving itself using context from wherever it operates.
If I leave this company tomorrow, the personal infrastructure is clearly mine. But what about the work-specific knowledge layered on top? The patterns learned in company context? The skills refined while solving company problems?
This isn’t a legal question. It’s an architecture question.
The Knowledge Accumulation Problem
Last post, I explored how AI agents operate under borrowed identity. This post addresses a related but distinct problem: what happens to the knowledge those agents accumulate?
Consider a developer who uses an AI assistant for two years:
- The AI learns their coding patterns and preferences
- It absorbs the codebase’s architectural conventions
- It understands why certain technical decisions were made
- It knows which approaches work and which don’t
- It has custom skills and workflows optimized for this environment
- It has accumulated feedback signals (ratings, corrections) that shape its behavior
- In advanced setups, it may have written its own skills based on what it learned
This isn’t hypothetical. If you’re using an AI assistant consistently for work, this is happening. The AI is learning—and in some frameworks, it’s learning how to learn better.
The question isn’t legal ownership (that’s for lawyers to sort out). The question is: where does this knowledge live, and what infrastructure decisions determine its portability?
The Knowledge Portability Spectrum
Not all knowledge is equally portable. I think about it as a spectrum:
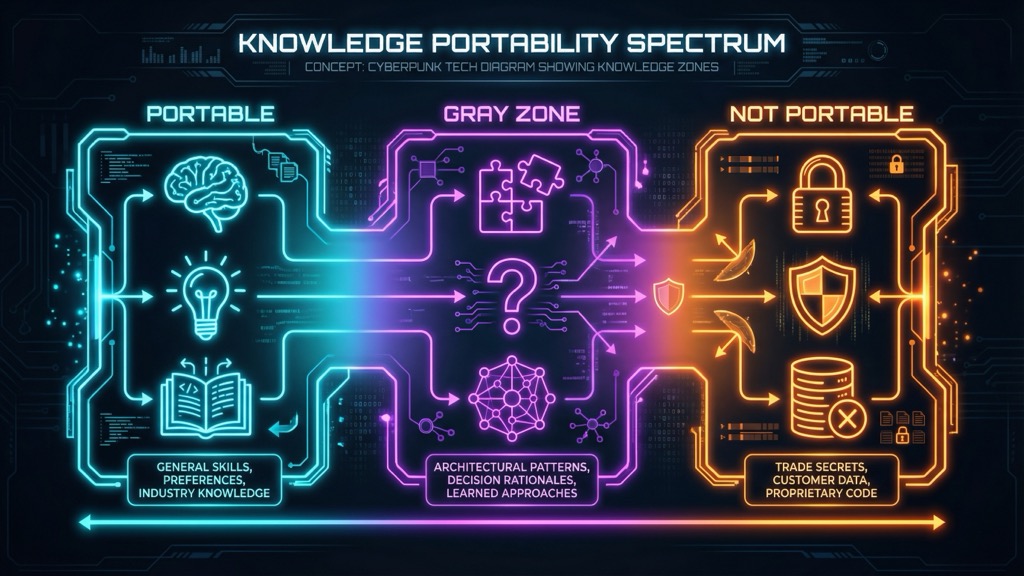
Clearly Portable
Some knowledge should move with you:
- General skills: How to write code, design systems, communicate effectively
- Personal preferences: Your coding style, your way of thinking through problems
- Industry knowledge: Patterns common across the industry, public best practices
- Learning: What you’ve learned about technologies, frameworks, approaches
An AI assistant incorporating these things is no different than you remembering them yourself. This is professional development.
Clearly Not Portable
Some knowledge should stay behind:
- Trade secrets: Proprietary algorithms, undisclosed business strategies
- Customer data: Client information, user data, business relationships
- Source code: The actual code you wrote for the company
- Internal systems: Specifics of proprietary platforms, internal tools
If your AI assistant has absorbed this knowledge, it shouldn’t leave with you.
The Gray Zone
Most knowledge lives in the middle:
- Architectural patterns: How this company structures systems (vs. how companies in general structure systems)
- Decision rationales: Why certain choices were made (institutional memory)
- Failure patterns: What approaches didn’t work here and why
- Problem-solving approaches: Methods developed while working here
- Memory infrastructure: Not just the memories, but how they’re organized and retrieved
- Self-generated improvements: Skills the AI wrote for itself, prompt refinements it discovered
The recursive dimension is interesting: you used company time to train the AI, the AI used that training to write better skills, those skills make the AI more valuable. The improvement improves itself.
Why Infrastructure Design Matters
Here’s what I’ve learned: your infrastructure choices determine the answer to these questions before they’re even asked.
Where Context Lives
The fundamental choice is where your AI’s context and memory reside:
Local-first (context on your machine):
- You control what persists and what doesn’t
- Separation is your responsibility
- Portability is technically straightforward (if ethically clear)
- No third party holds your context
Cloud-hosted (context on provider infrastructure):
- Provider may enforce retention policies
- Enterprise plans often allow admin oversight
- Your context exists in someone else’s system
- Export options vary
Enterprise-managed (company-controlled infrastructure):
- Company can audit what the AI “knows”
- Exit procedures are their call
- Separation happens at their layer, not yours
- Cleaner boundaries but less personal control
The Memory Problem Compounds
This matters more as AI systems get better at remembering. Consider:
- Session context: Cleared when the conversation ends. Low risk.
- Persistent memory: Survives across sessions. Medium risk—depends on what’s stored.
- Learned patterns: The AI behaves differently based on accumulated experience. Higher risk—harder to isolate.
- Self-written skills: The AI has modified its own capabilities. Highest complexity—the improvement is entangled with the context that created it.
The more sophisticated your AI infrastructure, the harder it becomes to separate “what’s mine” from “what I learned here.”
The Self-Improvement Recursion
Advanced AI setups can improve themselves. My personal infrastructure includes:
- Signal capture (ratings that shape behavior)
- Skill generation (AI writes new skills based on what works)
- Workflow optimization (patterns that emerge from repeated use)
When the AI writes a skill that makes it better at a task, and that skill was written using context from a specific environment… the ownership question gets recursive.
I don’t have a clean answer to this. I don’t think anyone does yet.
Practical Scenarios
Let me walk through what this looks like in practice:
The Developer Transition
Situation: You’ve used AI extensively for two years. You’re moving to a new role.
What you’re taking:
- Your AI assistant configured with general coding patterns
- Skills and workflows you developed for general problems
- Your prompting style and approach
What stays:
- Any context explicitly about this codebase
- Skills that only work with this company’s systems
- Memory of proprietary implementations
The practical question: Can you cleanly separate these? If your infrastructure makes separation easy (clear Layer 3/4 boundaries, explicit memory management), yes. If everything is tangled together in one persistent context… harder.
The Consultant Reality
Situation: You work with multiple clients, using the same AI assistant across engagements.
What happens:
- Client A’s patterns inform how the AI approaches Client B
- Cross-client learnings accumulate implicitly
- The AI gets better at “this type of problem” generally
The practical question: Is this knowledge transfer? Competitive intelligence? Or just expertise? Your infrastructure choice determines whether this even happens. Multi-context architectures keep things separate. Single-context setups blend everything.
The Startup-to-Enterprise Move
Situation: You built sophisticated AI infrastructure at a startup. Now you’re joining a larger company.
What’s interesting:
- The patterns and approaches are yours
- The specific skills might reference startup-specific things
- The enterprise likely has its own AI infrastructure
The practical question: Do you start fresh? Migrate selectively? Your ability to do either depends on how you built the original setup.
What You Can Do
If you’re building AI infrastructure now—and you should be—here’s what I’d consider:
Design for Separation
Build your setup with explicit boundaries from the start:
- Layer separation: Keep personal context (Layer 4) cleanly separate from work context (Layer 3)
- Explicit memory management: Know what your AI remembers and where it’s stored
- Portable vs. non-portable skills: Build skills that are generalizable; document which ones are environment-specific
Choose Local-First Where Possible
I run my personal AI infrastructure locally because:
- I control what persists
- I can audit what’s stored
- Portability is a configuration choice, not a negotiation
- No third party makes decisions about my context
This isn’t always possible (some employers mandate specific tools), but where you have choice, local-first gives you options.
Document the Origin
When you develop something genuinely personal—an approach, a skill, a workflow—document that it’s yours:
- Keep personal experiments in personal contexts
- Note when a general skill was developed on your own time
- Maintain a clear sense of what came from where
This is less about legal protection and more about intellectual honesty with yourself.
Accept the Gray Zone
Some knowledge will be ambiguous. That’s okay. The goal isn’t perfect separation—it’s conscious design choices that make the boundaries as clear as possible given the complexity.
My Personal Setup
Here’s how I’ve architected my own separation:
Personal infrastructure (on my machine):
- Skills and workflows I’ve developed for general problems
- Memory of my approaches and patterns
- Experiments with new techniques
Work infrastructure (in work contexts):
- Company-specific configurations
- Project-specific memory
- Team conventions and patterns
The boundary:
- I don’t load work context into personal tools
- I don’t develop company-specific skills in personal infrastructure
- When I learn something general at work, I note it; when I implement it personally, I do so from scratch
Is this more work than a single unified setup? Yes. Does it mean I maintain two systems? Yes. But it also means the boundaries are clear—to me, to any employer, and to the AI itself.
The Bigger Picture
This is an architecture problem we’re all figuring out together. AI infrastructure is new enough that there aren’t established patterns yet.
What I know:
- Infrastructure design determines knowledge portability before any policy question arises
- Local-first gives you control that cloud-hosted approaches don’t
- Separation is easier to maintain than to create after the fact
- Self-improving systems complicate everything
The best time to think about these boundaries is when you’re building the infrastructure. The second-best time is now.
Next in this series: The Trust Ladder—a framework for calibrating AI autonomy to task risk.
Thinking about AI infrastructure architecture? Find me on X or LinkedIn.