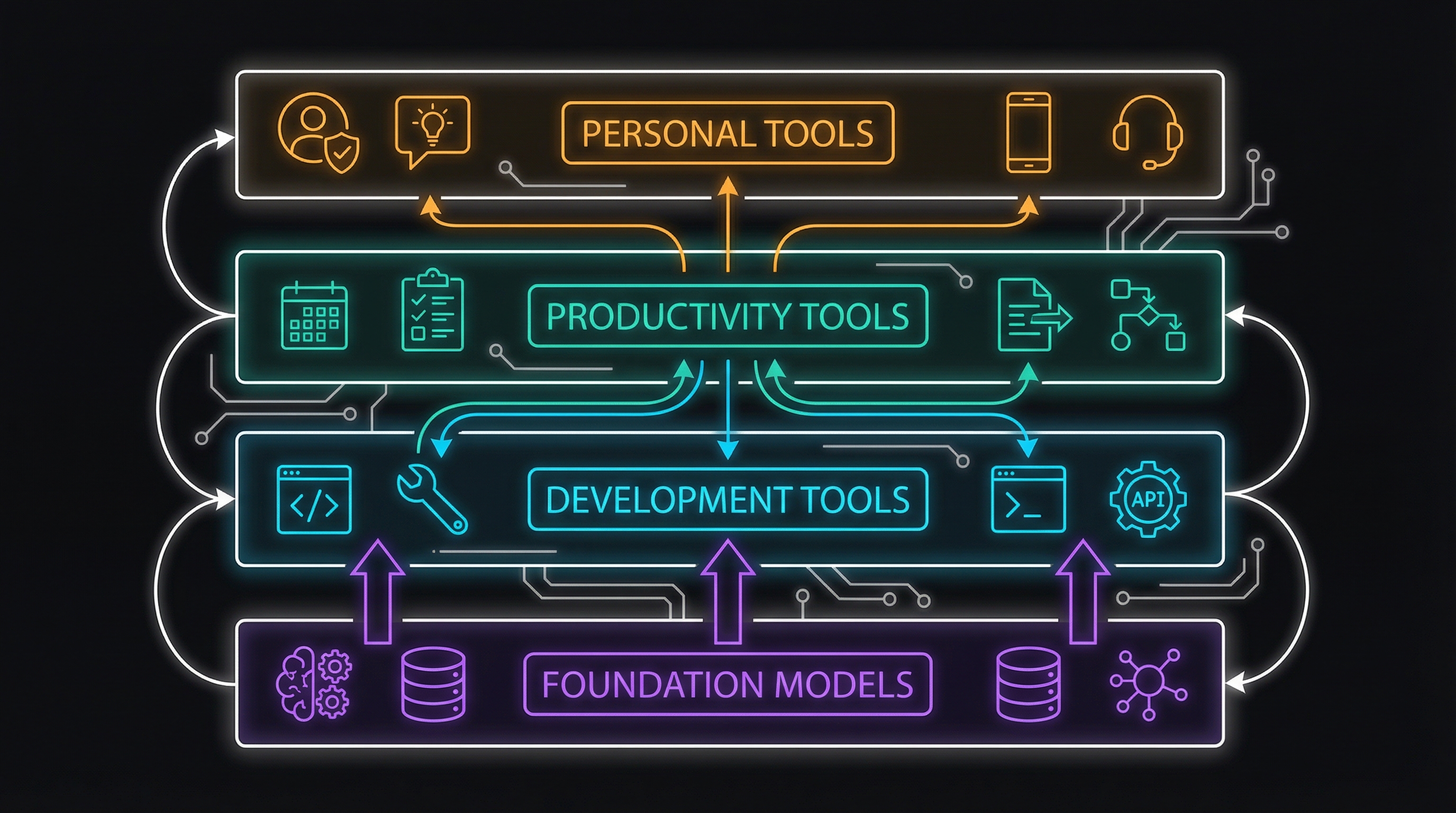
The Reference Architecture: A 4-Layer Approach to AI Tooling
The audit framework tells you which tools are problematic. It doesn’t tell you what to do about it.
“Use compliant alternatives” is easy advice to give and hard advice to follow. Which alternatives? How do they fit together? Where do boundaries belong? What’s the actual architecture of a compliant AI toolkit?
This post proposes a reference architecture—not specific products, but a structural approach to organizing AI capabilities in regulated environments. The goal is a framework you can adapt to your context, not a shopping list that’ll be outdated in six months.
The Four-Layer Model
I think about the regulated AI stack in four layers, each with different compliance requirements and context boundaries:
Layer 1: Foundation Models
The base layer is enterprise-managed access to foundation models. This isn’t ChatGPT or Claude’s consumer products—it’s AWS Bedrock, Azure OpenAI, Google Vertex AI, or self-hosted models.
Characteristics:
- Organization controls data flow and retention
- Audit logging at the API level
- Contractual terms negotiated by procurement
- Often the only AI capability explicitly approved by compliance
What lives here:
- API access to Claude, GPT-4, Gemini through cloud providers
- Self-hosted open-source models (Llama, Mistral)
- Fine-tuned models for specific use cases
Compliance posture: This layer typically passes the audit framework because your organization controls it. Data residency, retention, and access controls are configured by your enterprise agreement.
Layer 2: Development Tools
Layer 2 is where software gets built—IDE assistants, code generation, development workflows.
Characteristics:
- Tight integration with development environment
- Code flows through these tools constantly
- Needs to understand your codebase context
- Often connected to source control systems
What lives here:
- Enterprise GitHub Copilot or Amazon CodeWhisperer
- Claude Buddy for structured development workflows
- Code review assistants
- Documentation generators
Compliance posture: This layer requires enterprise agreements. Consumer-tier coding assistants typically fail the audit. The tools need to understand code context without leaking it, maintain audit trails of what was generated, and integrate with enterprise identity.
Layer 3: Productivity Tools
Layer 3 covers general knowledge work—writing, analysis, research, communication assistance.
Characteristics:
- Handles varied content types (documents, data, communications)
- Often processes customer-related information
- Needs to integrate with business systems
- High variability in data sensitivity
What lives here:
- Enterprise chat interfaces to Layer 1 models
- Document summarization and analysis tools
- Meeting transcription and notes
- Email and communication assistants
Compliance posture: This is where most shadow AI risk concentrates. Workers need these capabilities but often can’t get approved enterprise versions. The gap between what’s available and what’s approved drives people to consumer tools.
Layer 4: Personal Tools
Layer 4 is everything outside the enterprise perimeter—personal accounts, side projects, learning and exploration.
Characteristics:
- Hard-partitioned from enterprise data
- No organizational data ever touches this layer
- Personal accounts, personal devices
- Zero compliance obligation from employer
What lives here:
- Personal ChatGPT, Claude, or other AI subscriptions
- Side project development
- Learning and experimentation
- Personal productivity assistance
Compliance posture: This layer doesn’t need to comply with enterprise requirements—it just needs to stay completely separate. The architecture’s job is to make that separation clear and maintainable.
Context Flow Boundaries
The four layers aren’t just organizational—they define where data can and cannot flow.
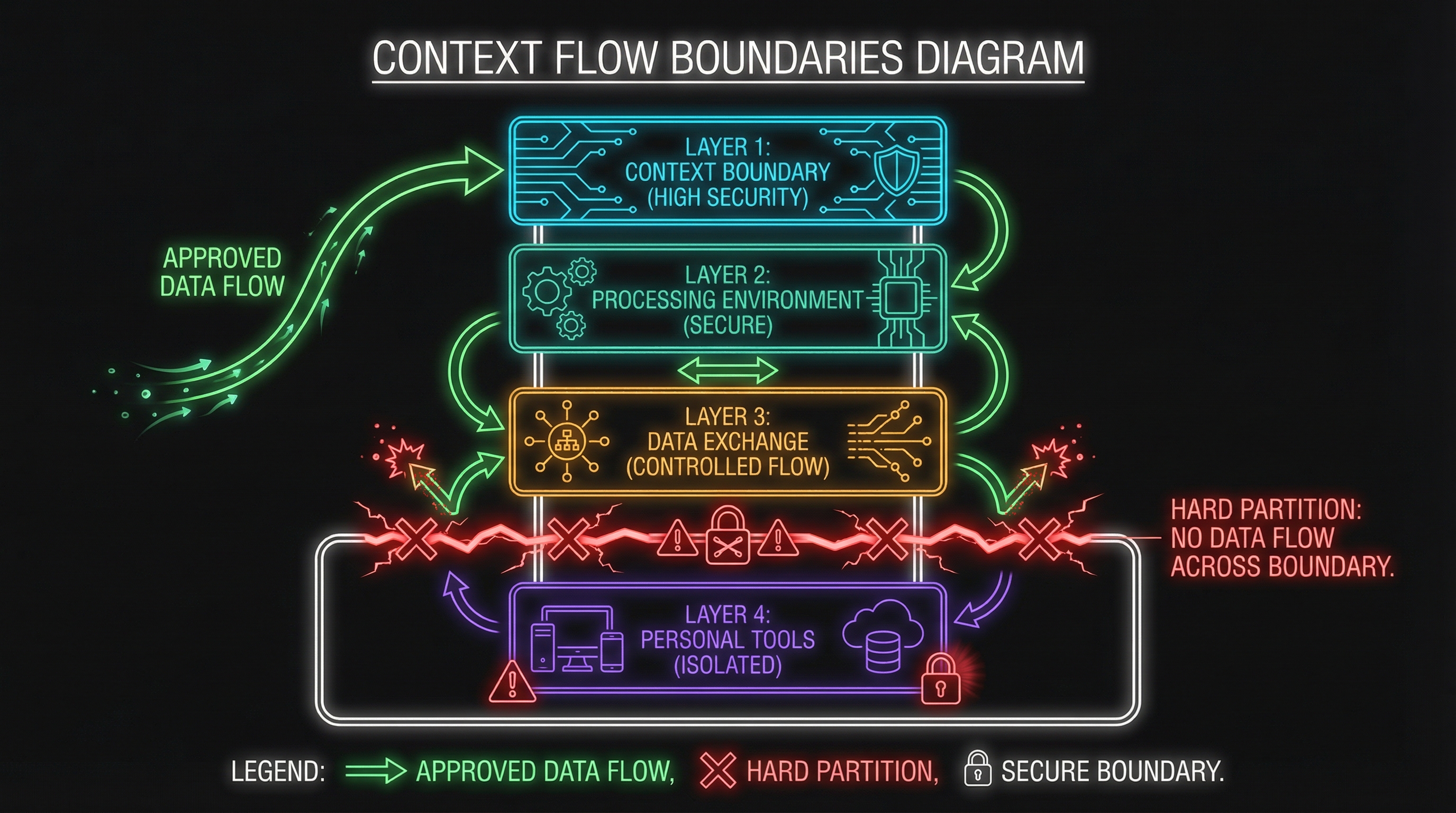
Permitted Flows (Layers 1-2-3)
Within the enterprise stack (Layers 1-3), context can flow up and down:
- Layer 1 → Layer 2: Foundation models power development tools
- Layer 2 → Layer 3: Code context can inform productivity tools (with appropriate controls)
- Layer 3 → Layer 1: User queries flow to foundation models
- Bidirectional: Models learn from enterprise data, enterprise data gets processed by models
The key: all of this happens within the compliance perimeter. Data residency, retention, and audit requirements apply uniformly.
Hard Boundary (Layer 3 → Layer 4)
The boundary between Layer 3 and Layer 4 is absolute. No organizational data flows to personal tools. Ever.
This sounds obvious, but it’s where the architecture usually fails in practice. Someone uses personal Claude to “quickly check something” about a customer situation. Someone pastes meeting notes into personal ChatGPT. The boundary erodes through convenience.
The architecture needs to make the boundary:
- Visible: Workers should always know which layer they’re in
- Convenient to respect: Enterprise alternatives should be good enough
- Enforceable: Technical controls where possible, policy controls where necessary
The Reality of Layer 4
I want to be clear about Layer 4: it’s not a compliance problem to solve. People should have personal AI tools. Personal learning, personal projects, personal productivity—none of that is the employer’s business.
The architecture’s job isn’t to eliminate Layer 4. It’s to make the boundary between Layer 3 and Layer 4 crisp. Personal tools stay personal. Work tools stay work. The problems arise when they mix.
Implementing the Architecture
How do you actually build this? Some practical approaches:
Layer 1: Foundation Model Access
Options:
- AWS Bedrock (Claude, Llama, others)
- Azure OpenAI (GPT-4)
- Google Vertex AI (Gemini)
- Self-hosted (Llama, Mistral via vLLM or similar)
Implementation pattern: API gateway with authentication, logging, and rate limiting. All upper-layer tools connect through this gateway, not directly to model providers.
Compliance controls: Data residency configured at cloud provider level. Retention policies enforced at gateway. Audit logs flow to SIEM.
Layer 2: Development Tools
Options:
- GitHub Copilot Business/Enterprise
- Amazon CodeWhisperer Professional
- Claude Code (via API to Layer 1)
- Claude Buddy for workflow governance
Implementation pattern: IDE plugins connect to enterprise-managed instances. Code snippets processed through Layer 1 models with appropriate logging.
Compliance controls: Enterprise identity (SSO). Code classification checks before submission to models. Audit trail of generated vs. human code.
Layer 3: Productivity Tools
Options:
- Custom chat interface to Layer 1 models
- Enterprise agreements with Claude/OpenAI (API access, not consumer apps)
- Microsoft 365 Copilot
- Custom-built tools for specific workflows
Implementation pattern: This layer often requires custom development. Off-the-shelf tools rarely meet specific compliance requirements. Build internal chat interfaces that connect to Layer 1 with appropriate guardrails.
Compliance controls: Data classification prompts before submission. Automatic PII detection. Conversation retention aligned with records policy.
Layer 4: Personal (Boundary Only)
The architecture doesn’t implement Layer 4—it just enforces the boundary. Approaches:
Technical:
- Enterprise browser profiles that block personal AI tools
- Network-level restrictions on corporate networks
- MDM policies on managed devices
Policy:
- Clear guidance on what constitutes “personal” vs. “work” data
- Training on recognizing boundary situations
- Consequences for violations (proportionate to risk)
Cultural:
- Make Layer 3 tools good enough that personal tools aren’t tempting
- Acknowledge that people will use personal AI for personal purposes
- Focus on the boundary, not on surveillance
Gaps in the Architecture
Let me be honest about what’s missing from this model:
The Layer 3 Gap
The biggest gap is Layer 3 tooling. Most organizations have decent Layer 1 access and reasonable Layer 2 options. Layer 3—the everyday productivity tools—is where the market hasn’t caught up.
Enterprise versions of popular AI tools are expensive, often feature-limited, and frequently awkward to use compared to consumer versions. This is why shadow AI happens.
What’s needed: More investment in building internal Layer 3 tools, or pressure on vendors to offer true enterprise-grade productivity features.
Context Continuity
Another gap: context doesn’t flow naturally between layers. Your Layer 2 development tool doesn’t know what you discussed in Layer 3. Your Layer 3 productivity tool doesn’t remember the architecture decisions from Layer 2.
In consumer AI, context flows everywhere—that’s part of what makes it useful. In the compliant stack, context is deliberately bounded, which creates friction.
What’s needed: Identity-aware context management that allows appropriate context sharing within compliance boundaries.
The Human Layer
The architecture describes tools. It doesn’t describe the human decisions that determine whether tools are used appropriately.
The best architecture fails if workers don’t understand it, don’t believe in it, or find it too inconvenient to follow. Training, culture, and incentives matter as much as technical controls.
What’s needed: A human integration layer that makes compliance the path of least resistance.
Building Toward the Ideal
The reference architecture isn’t a destination—it’s a direction. Most organizations can’t implement all four layers cleanly today. The value is in having a target state to build toward.
Near-term priorities:
- Establish solid Layer 1 foundation model access
- Deploy enterprise Layer 2 development tools
- Build minimal viable Layer 3 productivity tools
- Make the Layer 3/4 boundary explicit and visible
Medium-term evolution:
- Expand Layer 3 capabilities based on user feedback
- Implement context flow controls between layers
- Develop compliance dashboards and monitoring
- Iterate on the boundary based on what fails in practice
Long-term vision: A compliant AI stack that’s as capable and convenient as consumer alternatives, with the governance and auditability that regulated environments require.
This architecture provides the structural foundation. The next posts explore specific challenges: identity for AI agents, knowledge ownership, and trust calibration.
Implementing a layered AI architecture in your organization? I’d love to hear about your approach. Find me on X or LinkedIn.