
When Your Team Starts Building
Nobody in the room can quite explain what it did.
An engineer sets out to automate an API spec lifecycle: update the spec, publish it to the design portal, update the ticket. He loads a coding agent with context about the project, describes the goal, and lets it run. The agent asks for credentials, then navigates the design tool on its own, lists every spec in the registry, and cross-references them against the application catalog, a mapping no one explicitly described. When the room absorbs what had happened, someone says: “The only guy I know who understands how this works is Karpathy. And even he says he has no clue.”
That’s where we are.
What the Follow-On Prompt Produces
The setup is simple. After a team documents its daily processes (the diagnostic exercise from the previous post), the follow-on assignment is one notch further: from everything you documented, pick one step you’d hand to an agent first. Not the whole workflow. One step.
What comes back is not uniform, not polished, and not what you’d expect. Five engineers, five implementations, five different stages of completion, in a real environment with real deadlines and real compliance constraints. Not a proof of concept scheduled for a demo. Work in progress. Five patterns show up every time.
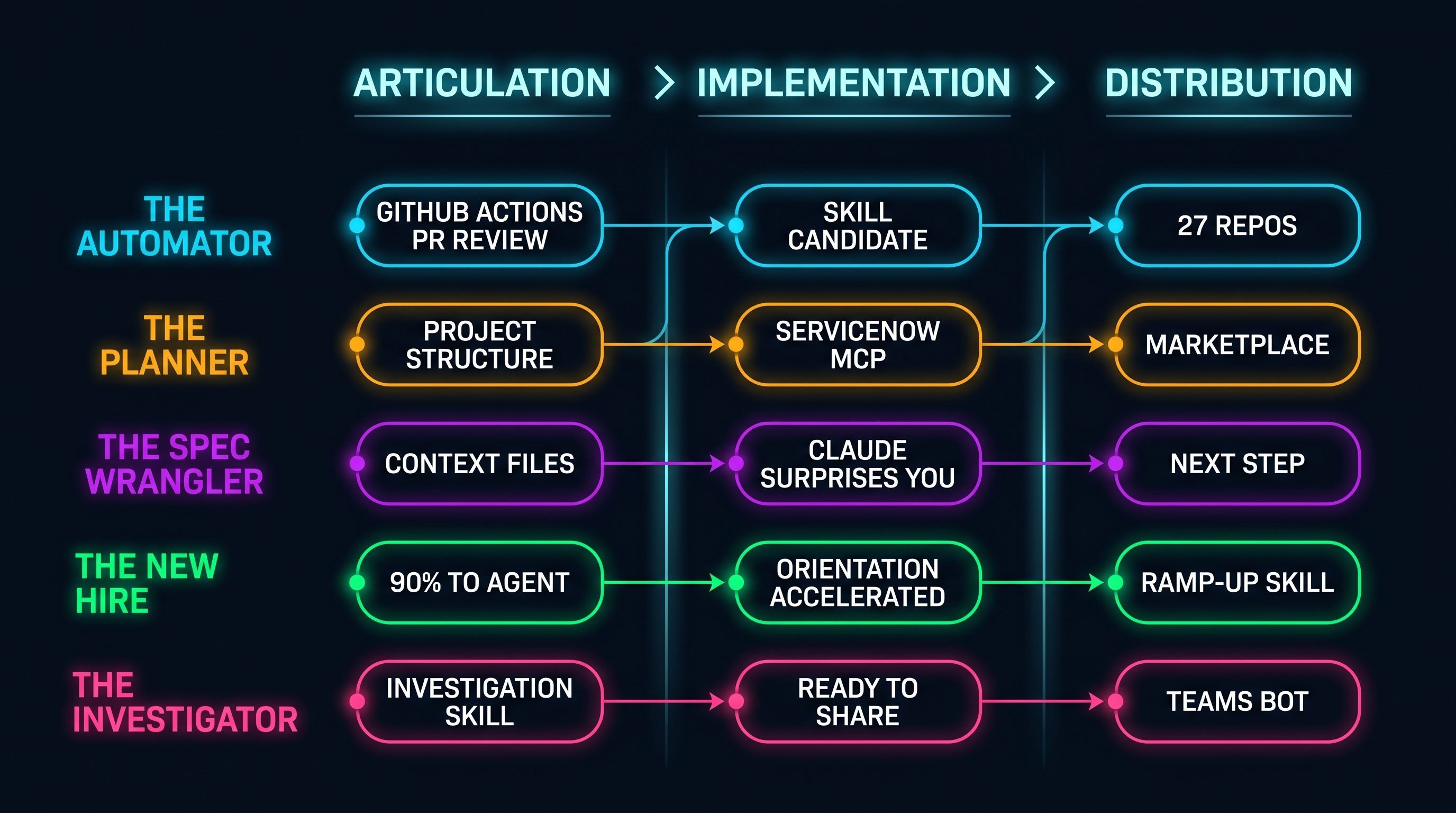
Five Builders
The automator. One engineer arrives with something already running for a couple of repositories. A CI workflow that triggers on every pull request, runs a coding agent against the diff, compares the changes to the team’s documented standards (naming conventions, masking requirements, commit formats), and posts a structured review comment before a human opens the tab. Offshore colleagues get feedback in seconds instead of waiting until morning. The hard part isn’t the agent; it’s the authentication in the CI context. The guidance that matters: encapsulate the review prompt as a reusable skill before propagating it across the rest of the repositories, the same way you’d centralize any shared pipeline configuration. The difference between one working tool and dozens that drift apart is whether it’s centralized. The hardest part of the demo isn’t the automation. It’s resisting the urge to ship before it’s stable.
The planner. Another engineer brings a structured project skeleton an agent generated from a description of the workflow he wants: aggregate requirements from a couple of systems, consolidate them into a daily digest, route them to the right people. Folder structure, module separation, file naming, all scaffolded from a conversation. The meaningful problem: his first prompt produced a web application. He didn’t want a UI. He wanted an agentic workflow, something that runs, fetches, correlates, and delivers without a browser in the loop. He refined the prompt until the shape of the output matched the shape of the solution. The guidance: point the work at the gaps, not the problems already solved. Directing an agent toward the unsolved ground is the skill.
The spec wrangler. This is the engineer who produces the moment nobody can explain. He’s building the API spec automation in stages: read the spec, apply changes based on requirements, publish the new version, notify the ticket. A workflow that costs a senior engineer an hour per change, sometimes more. He prepares context files and asks the agent to build something analogous for the spec layer. What the agent does is go further: it identifies the authentication pattern on its own, asks for credentials, connects to the design tool’s API, pulls the full registry, and starts cross-referencing. He ends the demo uncertain exactly what decision the agent made to take that path. This is the implementation gap: the distance between what you described and what the agent executed. It’s different from the context accumulation gap from the previous post. Here the agent didn’t do exactly what was planned, but what it did was useful. Learning to read that gap rather than fight it is its own engineering discipline.
The new hire. One engineer joined recently. Thirty years in the industry. First AI-assisted onboarding. He doesn’t have a defined pipeline of work yet; he’s in the absorption phase, learning the codebase and the tooling, building a picture of what exists before committing to what he wants to build. What he presents isn’t a finished skill. It’s a pattern. He sends most of his tasks to an agent first, not for coding but for orientation: which pull requests are pending, when a pipeline last ran for a given resource. The agent pulls from several tools at once without being told to coordinate them, and an investigation that would have taken 15 to 20 minutes of portal-clicking comes back in seconds. He’s building context in days instead of weeks. The suggestion: turn this into a ramp-up skill, a structured set of workflows that answer the questions every new engineer asks in the first 30 days. Onboarding happens often enough that compressing it is time you stop paying twice.
The investigator. The most production-ready build comes from the engineer closest to the support function. He builds an investigation skill on top of an observability connection. The use case recurs several times a week: a user reports a problem, and someone has to trace what happened. Manually that means filtering by time window, correlating session events, cross-referencing error codes against documentation. The skill does all of it from a single prompt: give it an account number, a reference ID, or a date range, and it reconstructs the full session timeline, maps events in sequence, and explains what happened. In one case a user-reported error traced back to a field-length limit, a value longer than the field allowed. Resolution took seconds. The same investigation, done manually, would have pulled several engineers into a channel for the better part of a morning. The result is a packaged skill, documented to a shared standard, ready to hand to anyone.
The Wall Everyone Hit
Across all five presentations, the same question surfaces:
How do I share this?
Every builder, independently, arrives at the distribution problem. The automator needs to propagate across the rest of the repositories. The planner wants something the whole team can install. The spec wrangler wants his context files and skill in a shared project. The investigator wants his skill out of his personal environment and into a form anyone can run. Even the new hire ends up with an assignment: codify the onboarding pattern so the next hire benefits.
That’s not a coincidence. It’s the structural problem that follows every successful implementation. Personal tool, team tool, shared registry, enterprise capability. The path is the same every time. What changes is how soon a team invests in the infrastructure that makes the transition possible. The organizational barriers to AI adoption usually aren’t the technology. They’re the systems and standards that decide what gets shared and what stays siloed. Without a shared registry, a review process, and a standard for what a publishable skill looks like, the default is accretion: everyone’s best tools stay on everyone’s own machine until they’re too outdated to run.
The action item that follows is direct: build a team standard for skill creation. What structure does a publishable skill follow? What review process does it go through? That’s the next agenda, not more implementations, but the infrastructure that turns implementations into shared capability.
The Ramp-Up Question
The new hire’s experience is worth returning to, because it gets overlooked when you’re surrounded by engineers deep in the tooling. Thirty years in the industry, and his previous onboarding meant a couple of engineers, hours of shadowing daily, weeks before he could move independently. This time, with the right skills loaded, he could absorb in a couple of days what used to take weeks, not at the depth of someone who’s been there for years, but enough to start contributing and hold a meaningful conversation about the system.
That’s a structurally different kind of onboarding, and it points at something worth documenting as a formal artifact: not a wiki page, not a slide deck, but a working ramp-up skill with executable workflows. Where does code live, how does a change move from local to production, what naming conventions apply, who owns what. Useful the day someone joins, and decaying in usefulness as answers change, which makes it a forcing function for keeping documentation current. The team that builds it has a structural advantage. Not in the interview room. In week three.
The Question That Had to Be Asked
In a session like this, the sharpest question almost always comes from the room. During the investigator’s demo, another engineer raised his hand: if you give the skill an account number and it reconstructs the full user session, can you identify the individual?
It’s the right question, and it surfaces the thing that needs the most care in a regulated environment. The sound answer is that masking belongs at the source: personally identifiable information stripped at the application layer before anything reaches the observability platform, so what the skill sees is session data, error codes, reference IDs. It can identify what happened. It can’t identify who, by design.
But the question matters more than the answer. An engineer who raises it during a live demo, not in a compliance review six months later, not after an incident, is exactly the culture that makes AI adoption in a regulated environment sustainable. The instinct to ask “but what about PII?” doesn’t need to be trained into people who’ve been working in financial services long enough. What needs to exist is an environment where that instinct is acted on, in the moment, before the tool ships. When that conversation happens in the working session, that is where it belongs.
The Infrastructure of Intelligence
The pattern across all five implementations runs the same way: articulation enabled action, action produced a working tool, and the working tool immediately revealed a distribution problem.
That sequence isn’t unique to any one team. It’s what a real AI transformation looks like at the session level. The first skill is always personal. The first useful skill always wants to become a team resource. The question is whether the team has the infrastructure to support that transition, or whether useful tools stay siloed until they’re no longer useful to the one person who built them.
The next step is building that standard. That’s the work that turns five individual builders into a team that compounds.
If you’re running an AI transformation in a regulated environment and hitting the same distribution wall (how skills move from personal to shared) I’d be curious what you’re finding. Find me on X @orestesgarcia or LinkedIn /in/setsero.
Related: Same Question, Different Worlds: the session that set this in motion, and what the five different mental models revealed about where a team stands.