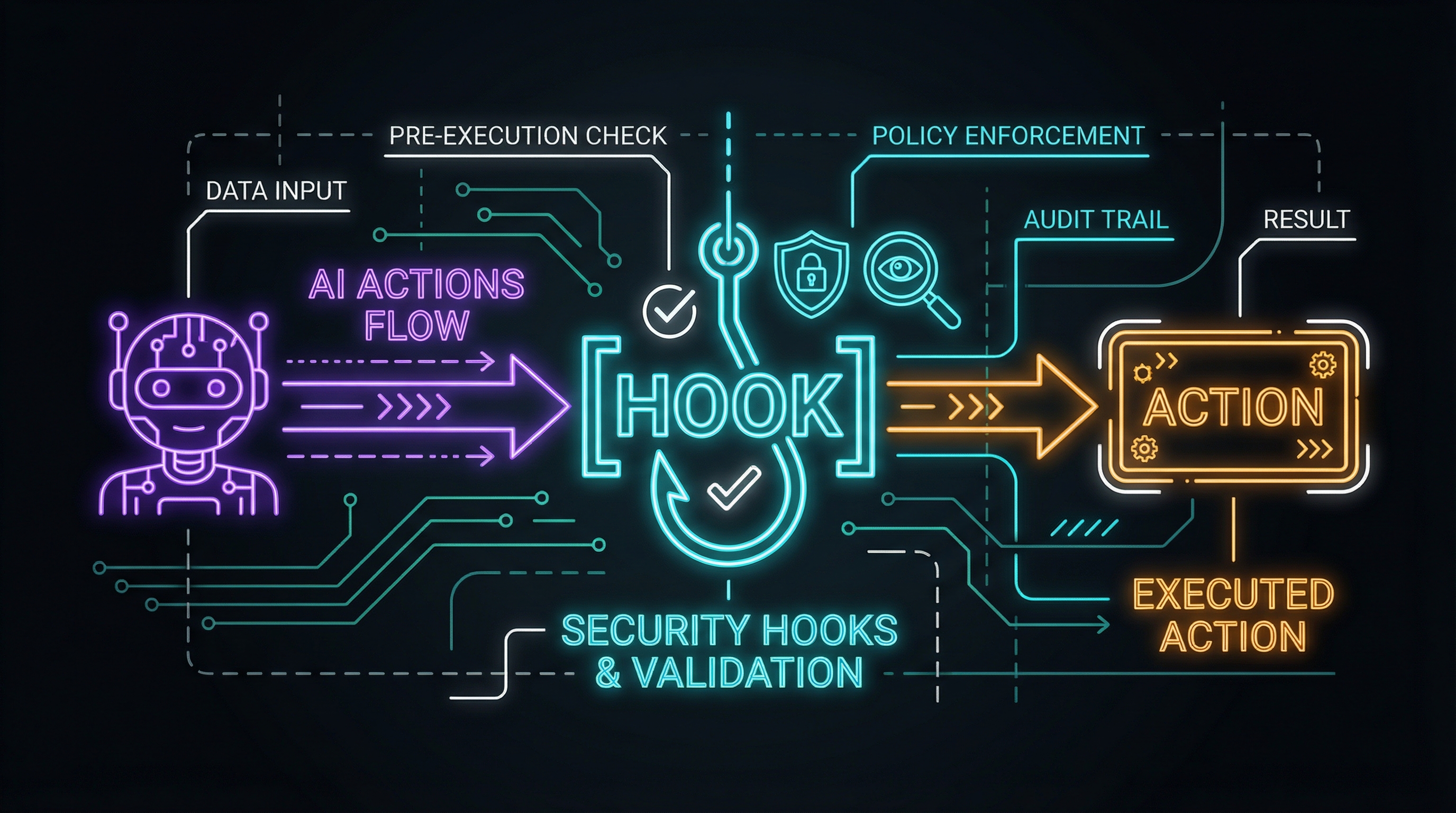
Validation Hooks: The Technical Foundation for Higher Trust
The Trust Ladder describes where you want to be. Validation hooks are how you get there.
You can’t move from “review everything” to “spot-check” based on vibes. You need systems that verify AI output, flag problems, and build the evidence base for trust graduation. Without this infrastructure, higher trust levels are aspirational at best, reckless at worst.
This post goes technical. We’re building the validation architecture that enables sustainable AI autonomy.
The Hook Pattern
Anthropic’s Claude Code hooks provide exactly this pattern for agentic workflows: deterministic checkpoints where agent execution pauses for validation before proceeding.
The core insight: agents shouldn’t complete tasks in one continuous flow. They should attempt to stop at defined points, triggering validation logic that decides whether to proceed or escalate.
I’m extending this into a more complete validation hook architecture with pre-execution gates, post-execution verification, and confidence scoring.
Architecture Overview
The validation pipeline has five stages:
Stage 1: AI Action
The agent attempts an action: commit code, create a file, make an API call, send a message. This is the trigger.
Stage 2: Pre-Hook Validation
Before the action executes, a pre-hook evaluates:
- Is this action within scope for this agent?
- Does it violate any hard constraints?
- Does it require additional authorization?
Pre-hooks are fast, deterministic gates. They either allow or block.
Stage 3: Execution
If pre-hooks pass, the action executes. This is where actual work happens.
Stage 4: Post-Hook Verification
After execution, post-hooks evaluate the result:
- Did the action produce expected output?
- Does the output meet quality thresholds?
- Are there anomalies or warning signs?
Post-hooks are more complex than pre-hooks. They can involve AI-powered verification, test execution, or heuristic analysis.
Stage 5: Confidence Scoring
Post-hook results feed a confidence score:
- High confidence: Action succeeded, output is good
- Medium confidence: Action completed but with warnings
- Low confidence: Significant concerns requiring review
Decision: Pass or Escalate
Based on confidence:
- High confidence → Task completes successfully
- Medium confidence → Completes with logged warnings
- Low confidence → Escalates for human review
Pre-Hook Implementation
Pre-hooks are your first line of defense. They should be fast and deterministic.
Scope Validation
Check that the action is within the agent’s permitted scope:
// pre-hooks/scope-validation.ts
interface ScopeConfig {
allowedPaths: string[];
blockedPaths: string[];
allowedActions: ('create' | 'modify' | 'delete' | 'commit')[];
maxFilesPerAction: number;
}
async function validateScope(
action: AgentAction,
config: ScopeConfig
): Promise<ValidationResult> {
// Check path restrictions
if (action.paths.some(p => isBlocked(p, config.blockedPaths))) {
return {
passed: false,
reason: 'Action targets blocked path',
severity: 'critical'
};
}
// Check action type
if (!config.allowedActions.includes(action.type)) {
return {
passed: false,
reason: `Action type '${action.type}' not permitted`,
severity: 'critical'
};
}
// Check file count
if (action.paths.length > config.maxFilesPerAction) {
return {
passed: false,
reason: `Too many files (${action.paths.length} > ${config.maxFilesPerAction})`,
severity: 'warning'
};
}
return { passed: true };
}Pattern Blocklist
Block known-problematic patterns before they execute:
// pre-hooks/pattern-blocklist.ts
const BLOCKED_PATTERNS = [
/process\.env\.\w+\s*=/, // Setting env vars
/require\(['"]child_process['"]\)/, // Shell execution
/eval\(/, // Dynamic code execution
/fs\.rmdirSync.*recursive:\s*true/, // Recursive deletion
/git\s+push\s+--force/, // Force push
];
async function validatePatterns(
action: AgentAction
): Promise<ValidationResult> {
if (action.type !== 'modify' && action.type !== 'create') {
return { passed: true };
}
for (const pattern of BLOCKED_PATTERNS) {
if (pattern.test(action.content)) {
return {
passed: false,
reason: `Blocked pattern detected: ${pattern.source}`,
severity: 'critical'
};
}
}
return { passed: true };
}Authorization Check
Some actions require explicit authorization beyond default permissions:
// pre-hooks/authorization.ts
interface AuthorizationRequirement {
actionPattern: RegExp;
requiredLevel: 'explicit' | 'batch' | 'policy';
escalateTo: string;
}
const AUTHORIZATION_REQUIREMENTS: AuthorizationRequirement[] = [
{
actionPattern: /commit.*main/,
requiredLevel: 'explicit',
escalateTo: 'tech-lead'
},
{
actionPattern: /delete.*production/,
requiredLevel: 'explicit',
escalateTo: 'ops-team'
},
{
actionPattern: /modify.*config/,
requiredLevel: 'batch',
escalateTo: 'session-owner'
}
];
async function validateAuthorization(
action: AgentAction,
sessionContext: SessionContext
): Promise<ValidationResult> {
for (const req of AUTHORIZATION_REQUIREMENTS) {
if (req.actionPattern.test(action.description)) {
if (!hasAuthorization(sessionContext, req)) {
return {
passed: false,
reason: `Requires ${req.requiredLevel} authorization`,
severity: 'authorization',
escalateTo: req.escalateTo
};
}
}
}
return { passed: true };
}Post-Hook Implementation
Post-hooks verify execution results. They’re more complex and can involve AI-powered analysis.
Output Validation
Check that output meets structural expectations:
// post-hooks/output-validation.ts
interface OutputExpectation {
fileExists?: string[];
fileContains?: { path: string; pattern: RegExp }[];
testsPassing?: boolean;
lintPassing?: boolean;
}
async function validateOutput(
action: AgentAction,
result: ExecutionResult,
expectations: OutputExpectation
): Promise<ValidationResult> {
const issues: string[] = [];
// Check file existence
if (expectations.fileExists) {
for (const path of expectations.fileExists) {
if (!await fileExists(path)) {
issues.push(`Expected file not found: ${path}`);
}
}
}
// Check file content patterns
if (expectations.fileContains) {
for (const { path, pattern } of expectations.fileContains) {
const content = await readFile(path);
if (!pattern.test(content)) {
issues.push(`Expected pattern not found in ${path}`);
}
}
}
// Run tests if required
if (expectations.testsPassing) {
const testResult = await runTests();
if (!testResult.passed) {
issues.push(`Tests failing: ${testResult.failures.join(', ')}`);
}
}
if (issues.length === 0) {
return { passed: true };
}
return {
passed: false,
reason: issues.join('; '),
severity: issues.length > 2 ? 'critical' : 'warning'
};
}AI-Powered Verification
Use a separate AI call to verify output quality:
// post-hooks/ai-verification.ts
async function verifyWithAI(
action: AgentAction,
result: ExecutionResult
): Promise<ValidationResult> {
const verificationPrompt = `
Review this AI-generated output for quality and correctness.
TASK: ${action.description}
OUTPUT:
${result.content}
Evaluate:
1. Does the output address the task requirements?
2. Are there any obvious errors or bugs?
3. Does the code follow best practices?
4. Are there security concerns?
Respond with:
- CONFIDENCE: high/medium/low
- ISSUES: list any concerns
- RECOMMENDATION: proceed/review/reject
`;
const verification = await callVerificationModel(verificationPrompt);
return {
passed: verification.recommendation !== 'reject',
confidence: verification.confidence,
reason: verification.issues.join('; '),
severity: verification.confidence === 'low' ? 'critical' : 'info'
};
}Diff Analysis
For code modifications, analyze the diff:
// post-hooks/diff-analysis.ts
interface DiffMetrics {
linesAdded: number;
linesRemoved: number;
filesChanged: number;
riskScore: number; // 0-100
}
async function analyzeDiff(
action: AgentAction,
result: ExecutionResult
): Promise<ValidationResult> {
const diff = await getDiff(action.paths);
const metrics = calculateMetrics(diff);
// Large changes increase risk
if (metrics.linesAdded + metrics.linesRemoved > 500) {
return {
passed: true,
confidence: 'low',
reason: `Large change: ${metrics.linesAdded}+ / ${metrics.linesRemoved}-`,
severity: 'warning'
};
}
// High-risk file patterns
const riskPatterns = [
/security/i, /auth/i, /credential/i, /payment/i,
/config.*prod/i, /\.env/
];
const riskyFiles = action.paths.filter(p =>
riskPatterns.some(pattern => pattern.test(p))
);
if (riskyFiles.length > 0) {
return {
passed: true,
confidence: 'medium',
reason: `High-risk files modified: ${riskyFiles.join(', ')}`,
severity: 'warning'
};
}
return { passed: true, confidence: 'high' };
}Confidence Scoring
Aggregate post-hook results into an overall confidence score:
// confidence/scoring.ts
interface ConfidenceFactors {
outputValidation: ValidationResult;
aiVerification: ValidationResult;
diffAnalysis: ValidationResult;
historicalAccuracy: number; // 0-1, from past performance
}
function calculateConfidence(factors: ConfidenceFactors): ConfidenceScore {
// Weight different factors
const weights = {
outputValidation: 0.3,
aiVerification: 0.3,
diffAnalysis: 0.2,
historicalAccuracy: 0.2
};
// Convert to numeric scores
const scores = {
outputValidation: factors.outputValidation.passed ? 1 : 0,
aiVerification: confidenceToNumber(factors.aiVerification.confidence),
diffAnalysis: confidenceToNumber(factors.diffAnalysis.confidence),
historicalAccuracy: factors.historicalAccuracy
};
// Weighted average
const weightedScore = Object.entries(weights).reduce(
(sum, [key, weight]) => sum + scores[key] * weight,
0
);
// Critical failures override
const hasCritical = [
factors.outputValidation,
factors.aiVerification,
factors.diffAnalysis
].some(r => r.severity === 'critical');
if (hasCritical) {
return { level: 'low', score: weightedScore, override: 'critical-failure' };
}
// Thresholds
if (weightedScore > 0.8) return { level: 'high', score: weightedScore };
if (weightedScore > 0.5) return { level: 'medium', score: weightedScore };
return { level: 'low', score: weightedScore };
}
function confidenceToNumber(conf: string | undefined): number {
switch (conf) {
case 'high': return 1;
case 'medium': return 0.6;
case 'low': return 0.2;
default: return 0.5;
}
}Decision and Escalation
Based on confidence, decide whether to proceed or escalate:
// decision/escalation.ts
interface EscalationConfig {
trustLevel: number; // 0-4, from Trust Ladder
confidenceThresholds: {
proceed: number;
warn: number;
escalate: number;
};
escalationChannels: {
critical: string; // e.g., 'pager'
warning: string; // e.g., 'slack'
info: string; // e.g., 'log'
};
}
async function decide(
confidence: ConfidenceScore,
config: EscalationConfig
): Promise<Decision> {
// Adjust thresholds based on trust level
const adjustedThresholds = adjustForTrustLevel(
config.confidenceThresholds,
config.trustLevel
);
if (confidence.score >= adjustedThresholds.proceed) {
return {
action: 'proceed',
log: 'Action completed with high confidence'
};
}
if (confidence.score >= adjustedThresholds.warn) {
await notify(config.escalationChannels.warning, {
message: 'Action completed with warnings',
details: confidence
});
return {
action: 'proceed-with-warning',
log: 'Action completed with medium confidence'
};
}
// Escalate
await notify(config.escalationChannels.critical, {
message: 'Human review required',
details: confidence,
context: await gatherContext()
});
return {
action: 'escalate',
log: 'Action escalated due to low confidence'
};
}
// Higher trust levels have higher thresholds for escalation
function adjustForTrustLevel(
thresholds: { proceed: number; warn: number; escalate: number },
trustLevel: number
): typeof thresholds {
const adjustment = (4 - trustLevel) * 0.05; // Level 4 = no adjustment, Level 0 = +0.2
return {
proceed: Math.min(thresholds.proceed + adjustment, 0.95),
warn: Math.min(thresholds.warn + adjustment, 0.85),
escalate: Math.min(thresholds.escalate + adjustment, 0.7)
};
}Integration with Claude Buddy
Here’s how this architecture could integrate with Claude Buddy:
# claude-buddy.yml
validation:
pre_hooks:
- scope-validation
- pattern-blocklist
- authorization-check
post_hooks:
- output-validation
- ai-verification
- diff-analysis
confidence:
weights:
output_validation: 0.3
ai_verification: 0.3
diff_analysis: 0.2
historical: 0.2
thresholds:
proceed: 0.8
warn: 0.5
escalate: 0.3
escalation:
channels:
critical: slack://team-alerts
warning: log://warnings.log
info: log://info.log
trust_level_overrides:
implementation: 2 # Full review
documentation: 3 # Spot-check
testing: 3 # Spot-checkBuilding Trust Evidence
Validation hooks aren’t just protective—they generate the evidence needed to climb the trust ladder.
Tracking Accuracy
// metrics/accuracy-tracking.ts
interface AccuracyRecord {
timestamp: Date;
actionType: string;
preHookPassed: boolean;
postHookPassed: boolean;
confidence: ConfidenceScore;
humanOverride: boolean; // Did human change the decision?
actualOutcome: 'success' | 'failure' | 'unknown';
}
async function trackAccuracy(record: AccuracyRecord): Promise<void> {
await metricsStore.insert(record);
// Update rolling accuracy
const recent = await metricsStore.query({
actionType: record.actionType,
since: daysAgo(30)
});
const accuracy = recent.filter(r =>
r.postHookPassed && r.actualOutcome === 'success'
).length / recent.length;
await updateHistoricalAccuracy(record.actionType, accuracy);
}Graduation Reports
Generate reports to support trust level graduation:
// reports/graduation.ts
async function generateGraduationReport(
actionType: string,
targetLevel: number
): Promise<GraduationReport> {
const metrics = await metricsStore.query({
actionType,
since: daysAgo(30)
});
const criteria = getGraduationCriteria(targetLevel);
return {
actionType,
currentLevel: getCurrentTrustLevel(actionType),
targetLevel,
metrics: {
accuracy: calculateAccuracy(metrics),
volume: metrics.length,
escalationRate: calculateEscalationRate(metrics),
humanOverrideRate: calculateOverrideRate(metrics)
},
criteriaStatus: {
accuracyThreshold: {
required: criteria.accuracy,
actual: calculateAccuracy(metrics),
met: calculateAccuracy(metrics) >= criteria.accuracy
},
volumeThreshold: {
required: criteria.minVolume,
actual: metrics.length,
met: metrics.length >= criteria.minVolume
},
noEscapes: {
required: criteria.maxEscapes,
actual: countEscapes(metrics),
met: countEscapes(metrics) <= criteria.maxEscapes
}
},
recommendation: calculateRecommendation(metrics, criteria)
};
}The “Trust but Verify” System
Anthropic’s framing resonates: hooks provide deterministic control over agent behavior, ensuring certain actions always happen rather than relying on the LLM to choose. This isn’t about replacing trust with verification—it’s about building the verification systems that enable trust.
At Level 0, you verify everything because you have no evidence of reliability.
At Level 4, you verify outcomes because you have strong evidence of reliability.
The validation hooks don’t disappear as trust increases—they shift from per-action blocking to aggregate monitoring. The system remains observable, just with different thresholds for intervention.
This is “trust but verify” made systematic:
- Trust based on evidence
- Verification calibrated to risk
- Escalation when confidence is low
- Metrics that compound into organizational learning
Final post in this series: The 2026 Roadmap—synthesizing nine posts into concrete building priorities.
Implementing validation hooks in your AI workflows? I’d love to see what you’re building. Find me on X or LinkedIn.