The Trust Ladder: A Framework for Calibrating AI Autonomy
Every time I use Claude Buddy, I’m making an implicit trust decision.
Do I review this code line by line, or glance at the summary? Do I test this change manually, or trust the AI’s verification? Do I need to understand the implementation, or just confirm it works?
These decisions are usually unconscious—gut feel based on the task, my energy level, deadline pressure. But they shouldn’t be. Trust calibration is too important to leave to intuition.
This post proposes a framework: the Trust Ladder. Five levels of AI autonomy, matched to task risk, with explicit criteria for moving between them.
The Problem with Binary Trust
Most AI tooling assumes binary trust: either you review everything (treating AI like a junior developer) or you review nothing (treating AI like a reliable system).
Neither is right.
Reviewing everything negates the productivity benefit of AI. Reviewing nothing creates unacceptable risk—AI makes mistakes, models hallucinate, context gets confused. The answer is “review appropriately for the risk level.”
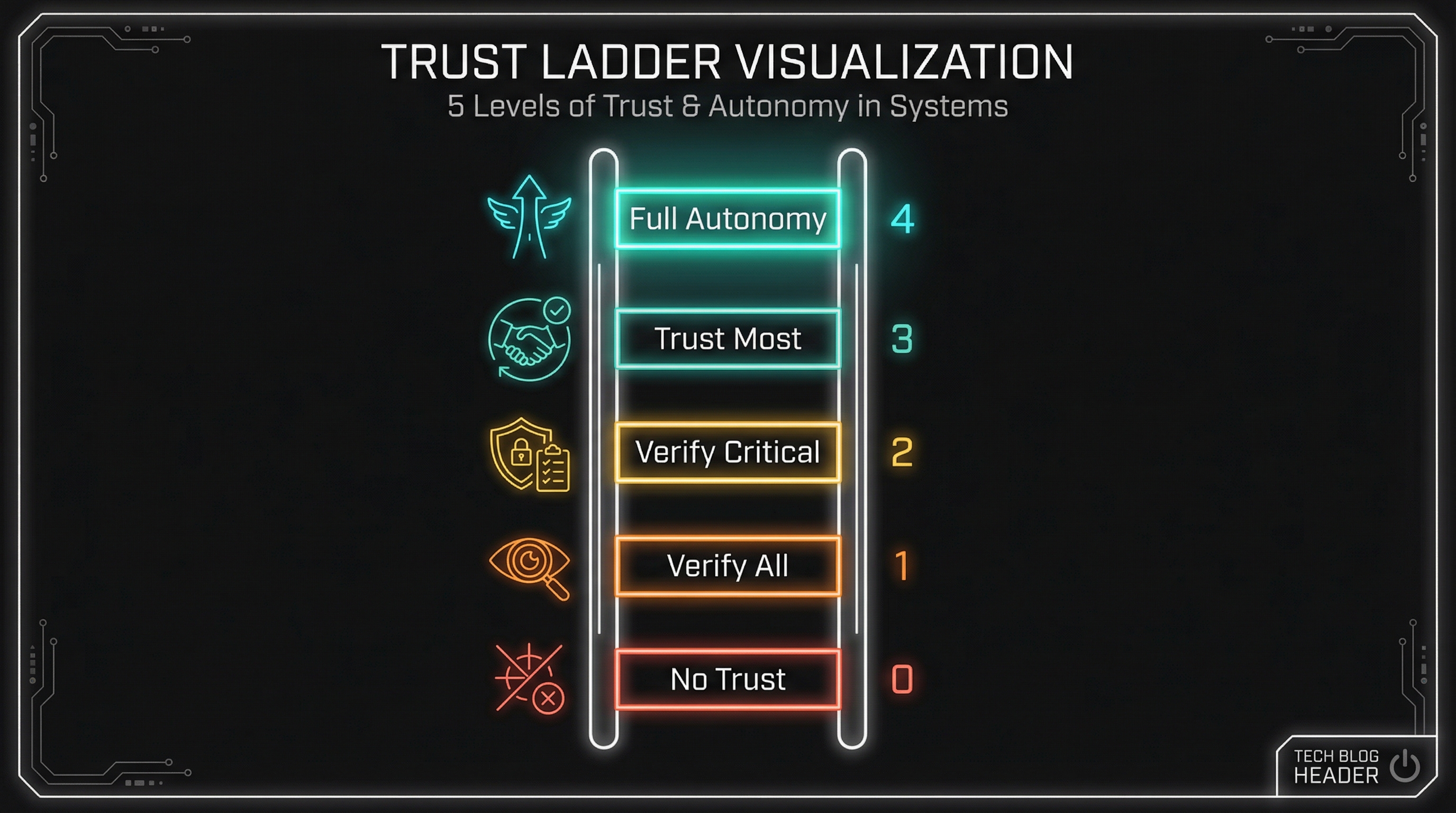
The Five Levels
I’ve organized trust into five levels, from maximum human control (Level 0) to maximum AI autonomy (Level 4):
Level 0: No Autonomy
AI role: None. Human does all work.
When to use: Tasks where AI provides no value or creates unacceptable risk—sensitive personnel decisions, strategic negotiations, work where AI disclosure creates legal issues.
Level 1: AI Suggests
AI role: Provides suggestions, references, or options. Human executes all actions.
When to use: Tasks where AI can speed up research or generate options, but execution must be human-controlled—initial research, brainstorming, finding references.
Level 2: AI Drafts, Human Reviews
AI role: Creates draft output. Human reviews everything before use.
When to use: Tasks where AI can produce reasonable first drafts, but output requires human verification—code implementation, document drafting, test creation, configuration changes.
Level 3: AI Executes, Human Spot-Checks
AI role: Completes tasks autonomously. Human reviews samples.
When to use: Tasks where AI has demonstrated reliability, and comprehensive review is inefficient—routine code changes, documentation updates, test additions for established patterns.
Level 4: AI Autonomous
AI role: Full autonomy within defined scope. Human monitors for anomalies.
When to use: Tasks where AI has proven highly reliable, risk is contained, and rollback is easy—automated testing, formatting, linting, status updates. Requires robust safety boundaries and rollback capability.
Parallel Frameworks: Trust Ladder and AIL
If you’ve read my post on agent impersonation, you encountered Daniel Miessler’s AI Influence Level (AIL) framework—a 0-5 scale for labeling AI involvement in content creation.
The Trust Ladder and AIL answer different questions about the same phenomenon:
Trust Ladder asks “How much oversight?” before work begins → Governance
AIL asks “How much AI?” after work is complete → Attribution
The levels map well:
- Level 0: AIL 0 (no AI involved) ↔ Trust 0 (no autonomy, human does all)
- Level 1: AIL 1 (minor AI assist) ↔ Trust 1 (AI suggests, human executes)
- Level 2: AIL 2 (major AI augmentation) ↔ Trust 2 (AI drafts, human reviews 100%)
- Level 3: AIL 3 (AI created, human structure) ↔ Trust 3 (AI executes, human spot-checks)
- Level 4: AIL 4-5 (AI created, minimal human) ↔ Trust 4 (AI autonomous, human monitors)
In practice, these frameworks are complementary. Trust Ladder decides oversight before work (“This documentation task is Level 3—I’ll spot-check 20%”), while AIL labels contribution after (“This document is AIL 3—AI created it, I provided structure”). Together they give you complete coverage: governance and attribution.
The agent impersonation problem I discussed in that earlier post requires both: content transparency (AIL) tells you what the AI contributed, while supervised identity (Trust Ladder governance) tells you who authorized it.
Mapping Tasks to Levels
Not all tasks should be at the same level. Risk varies by category:
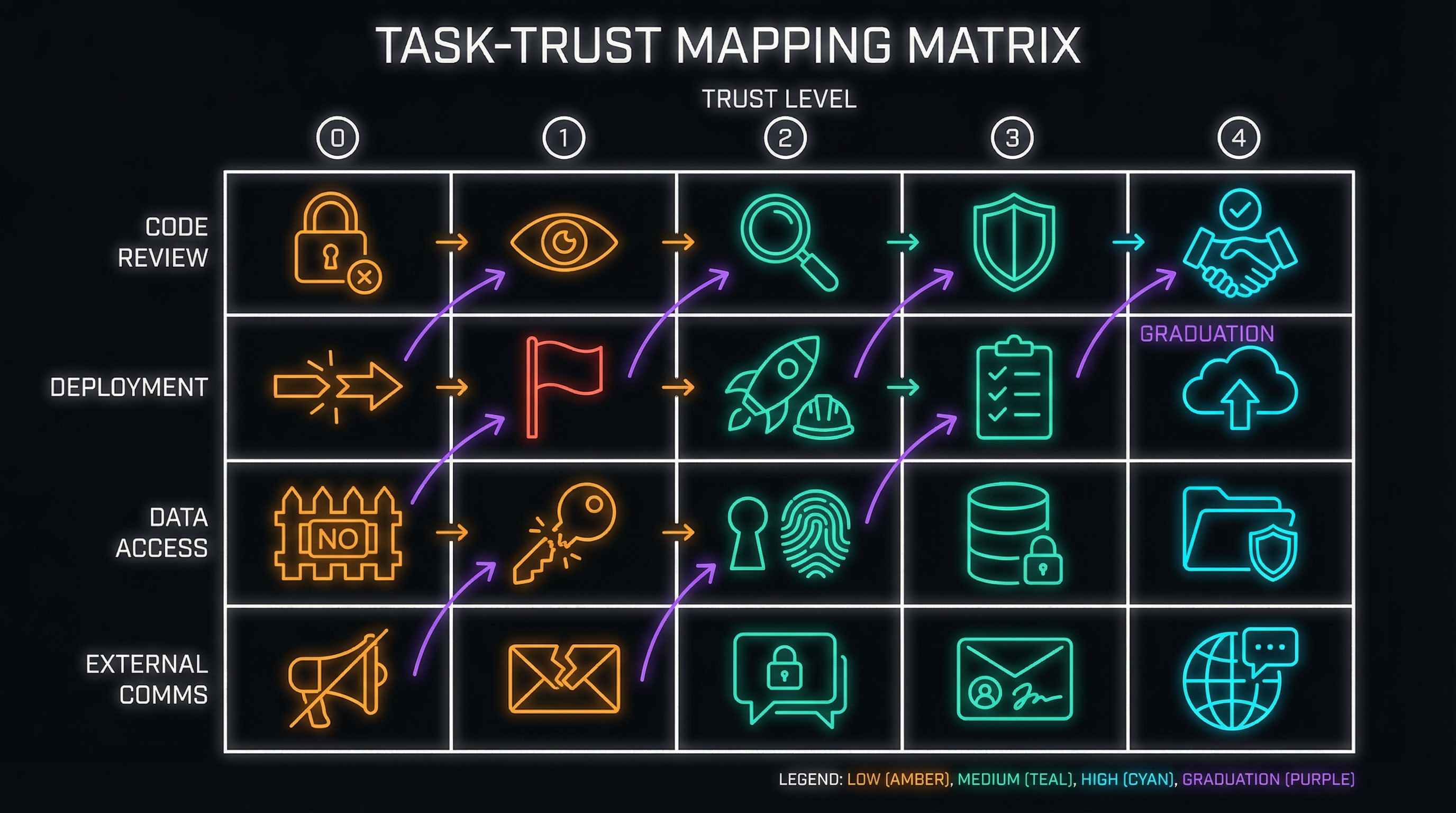
Documentation (Level 3-4): Low-impact errors, easily caught and fixed. Start at Level 2, graduate to 3 after consistent quality. Level 4 for truly routine updates.
Code Review (Level 1-2): AI surfaces issues well, but final judgment should be human. Level 3 possible for narrow categories (style, obvious bugs) after demonstrated accuracy.
Testing (Level 2-3): AI writes tests effectively, and failures are caught automatically. Level 2 for new tests, Level 3 for established patterns, Level 4 for execution and reporting.
Implementation (Level 2): Where AI shines but also where mistakes hit hardest. Start and often stay at Level 2. Level 3 only for well-defined changes to well-tested code.
Deployment (Level 0-1): Errors can be catastrophic. Level 0 for production in regulated environments. Level 1 for staging/dev. Level 2 requires extensive automation and rollback.
Graduation Criteria
Moving up the ladder requires evidence, not comfort. The key thresholds:
0 → 1 (Introduce suggestions): Task analyzed for AI applicability, no regulatory barriers, AI suggestions useful more often than not (>50% acceptance).
1 → 2 (AI creates drafts): Suggestions consistently meet quality bar, time savings exceed review overhead, drafts require only minor revisions (>70% content retained).
2 → 3 (Spot-check replaces full review): Track record of >95% accuracy, downstream validation catches errors, error cost is containable, spot-check process defined. Zero escapes to production for 30 days.
3 → 4 (Full autonomy): Extended >99% accuracy, automated anomaly monitoring, automatic rollback, clear scope boundaries, tested human intervention path. Measurable efficiency gain with no increase in incidents.
Operationalizing Trust Levels
Define trust levels in your AI tooling configuration:
trust_levels:
documentation:
level: 3
review_sampling: 20%
auto_approve: formatting-only
implementation:
level: 2
review_required: true
commit_requires: explicit-approval
deployment:
level: 0
ai_assistance: disabledWhen incidents occur, demote immediately: revert to a lower level, investigate root cause, remediate, and only return to the higher level after confidence is restored. Trust levels should also evolve organization-wide—set baselines per task category, allow individual variance with justification, and cap levels in regulated environments.
Common Mistakes
Premature graduation: Moving up before evidence supports it, usually from time pressure or normalizing small errors. Fix: require explicit evidence, track metrics, don’t skip levels.
Stuck at Level 2: Never graduating beyond full review due to risk aversion or not tracking accuracy. Fix: establish graduation criteria upfront, measure accuracy, accept that some risk enables efficiency.
Inconsistent application: Different trust levels based on mood or deadline rather than policy. Fix: configure levels in tooling, make decisions explicit.
Level 4 without infrastructure: Granting full autonomy without monitoring, rollback, or scope boundaries. Fix: Level 4 requires infrastructure investment—don’t grant autonomy without safety systems.
The Destination: Trust as Infrastructure
The goal isn’t to reach Level 4 everywhere. It’s to have the right trust level for each task, based on evidence, with infrastructure to support it—configuration that defines levels, metrics that track accuracy, processes that support graduation and demotion, and monitoring that catches anomalies.
This infrastructure doesn’t exist yet for most organizations. Building it is part of what makes AI adoption sustainable rather than chaotic.
Next in this series: Validation Hooks—the technical implementation that enables climbing the trust ladder.
Implementing trust calibration in your AI workflows? I’d love to hear your approach. Find me on X or LinkedIn.