AI Can Write Your Terraform. Can Your Organization Deploy It?
I asked Claude Code to generate a Terraform module for a multi-region AKS cluster with managed node pools and Azure CNI networking. It produced 200 lines of clean HCL in 90 seconds — proper tagging, NSGs scoped correctly, workload identity configured. The code was good. Better than the Stack Overflow copypasta that lives in half the production modules I’ve inherited.
The code wasn’t the problem. The problem was: where does it go? If your infrastructure changes flow through pull requests, CI/CD pipelines, and plan/apply gates, this is transformative. If your team is still clicking through the Azure Portal, AI-generated Terraform is a solution to a problem you haven’t solved yet.
Meanwhile, I pointed Claude Code at our Datadog MCP server and asked it to investigate a latency spike. It pulled logs, correlated traces, and built a comprehensive analysis notebook — and it didn’t need a GitOps pipeline to do it. Same AI, two completely different organizational prerequisites. That asymmetry is the story nobody’s telling.
The Code Is Better Than You Think
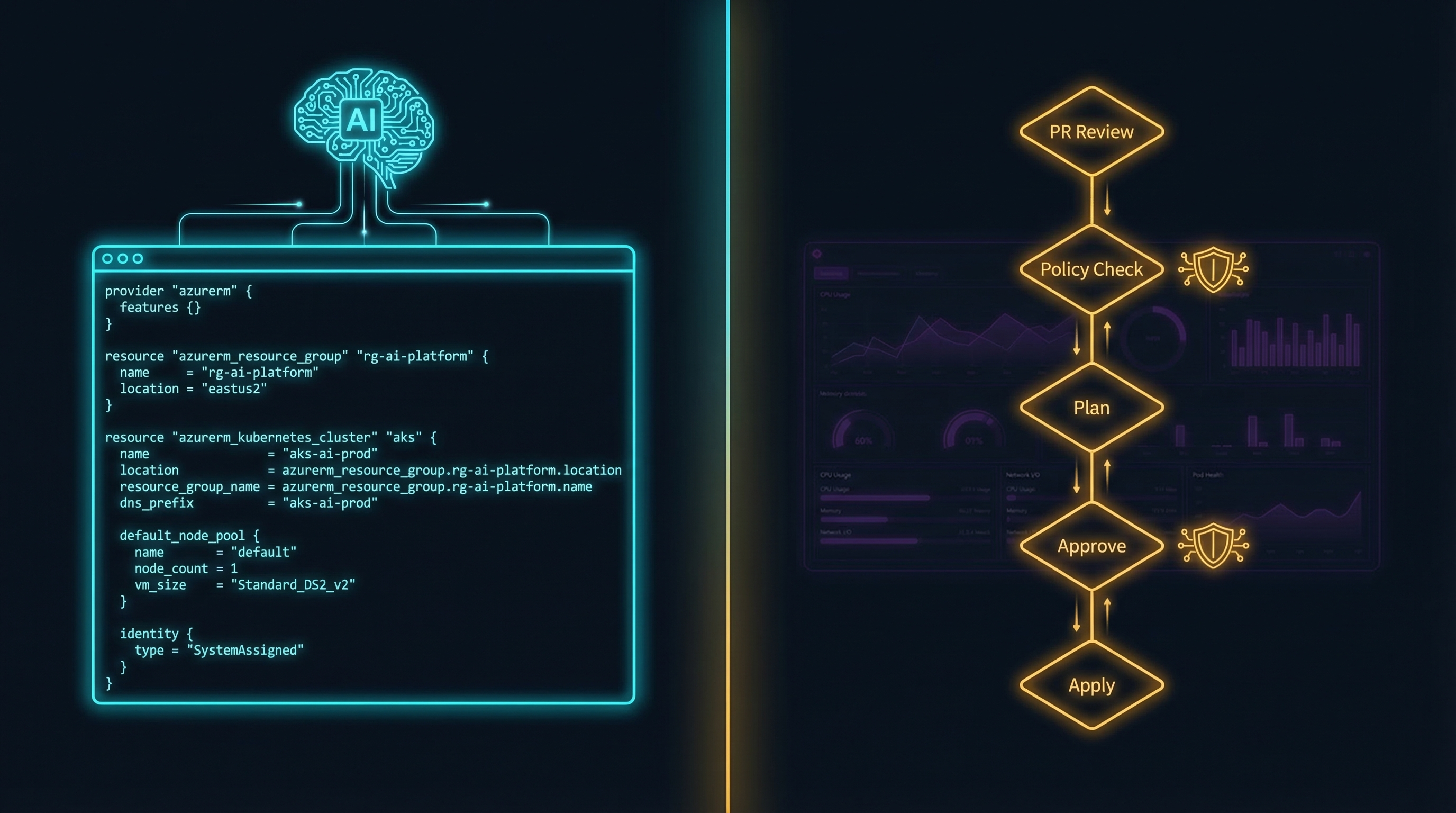
The tooling is real and it’s improving fast. The elluminate.de team runs Claude Code across three Kubernetes environments on two cloud providers. Their approach is deliberate: Claude Code can run kubectl get and tofu plan, but it can never execute tofu apply. The AI generates, the human reviews the plan output, and the pipeline applies. This is the pattern that works.
Anton Babenko — the most prolific Terraform module author in the community — built a Claude skill specifically for Terraform. That’s not a vendor demo. That’s the person who maintains the modules most of us depend on deciding this tool is worth encoding his expertise into.
The key insight from practitioners: encoding tribal knowledge in CLAUDE.md and custom skills turns AI from a generic code generator into a team-aware assistant. The elluminate team writes platform-specific gotchas directly into their configuration — “the clusterissuer is called cert-manager, not letsencrypt-prod” — and Claude Code learns them. Every undocumented convention that used to live in someone’s head now lives in a file the AI reads before generating a single line of HCL.
The “Almost Right” Problem
Here’s where it gets uncomfortable. Veracode’s 2025 GenAI Code Security Report tested over 100 LLMs across 80 coding tasks: 45% of AI-generated code introduced security vulnerabilities. Models got better at writing functional code but showed no improvement in writing secure code. Security performance remained flat regardless of model size or training sophistication.
For application code, “almost right” means a bug caught in testing. For infrastructure code, “almost right” means a misconfigured NSG in production. There are only about 500,000 public HCL repositories on GitHub — compared to millions for JavaScript or Python — which means inherently less robust Terraform training data. AI-generated Terraform consistently defaults to dev/test patterns: overly permissive RBAC, public endpoints, missing private link configurations. It generates what it sees most frequently in training data, and training data is overwhelmingly insecure.
The DataTalks.Club founder’s experience is the cautionary tale: he let Claude Code run Terraform commands without guardrails and destroyed 2.5 years of production data. The honest practitioner consensus lands somewhere near what Zachary Loeber wrote: “I’ve yet to see any LLM model create very good terraform, ever” — but 95% accuracy with human review is transformative. The trust ladder applies directly here: AI-generated IaC must stay at Level 1 — observe and advise, human decides.
The 89/6 Gap
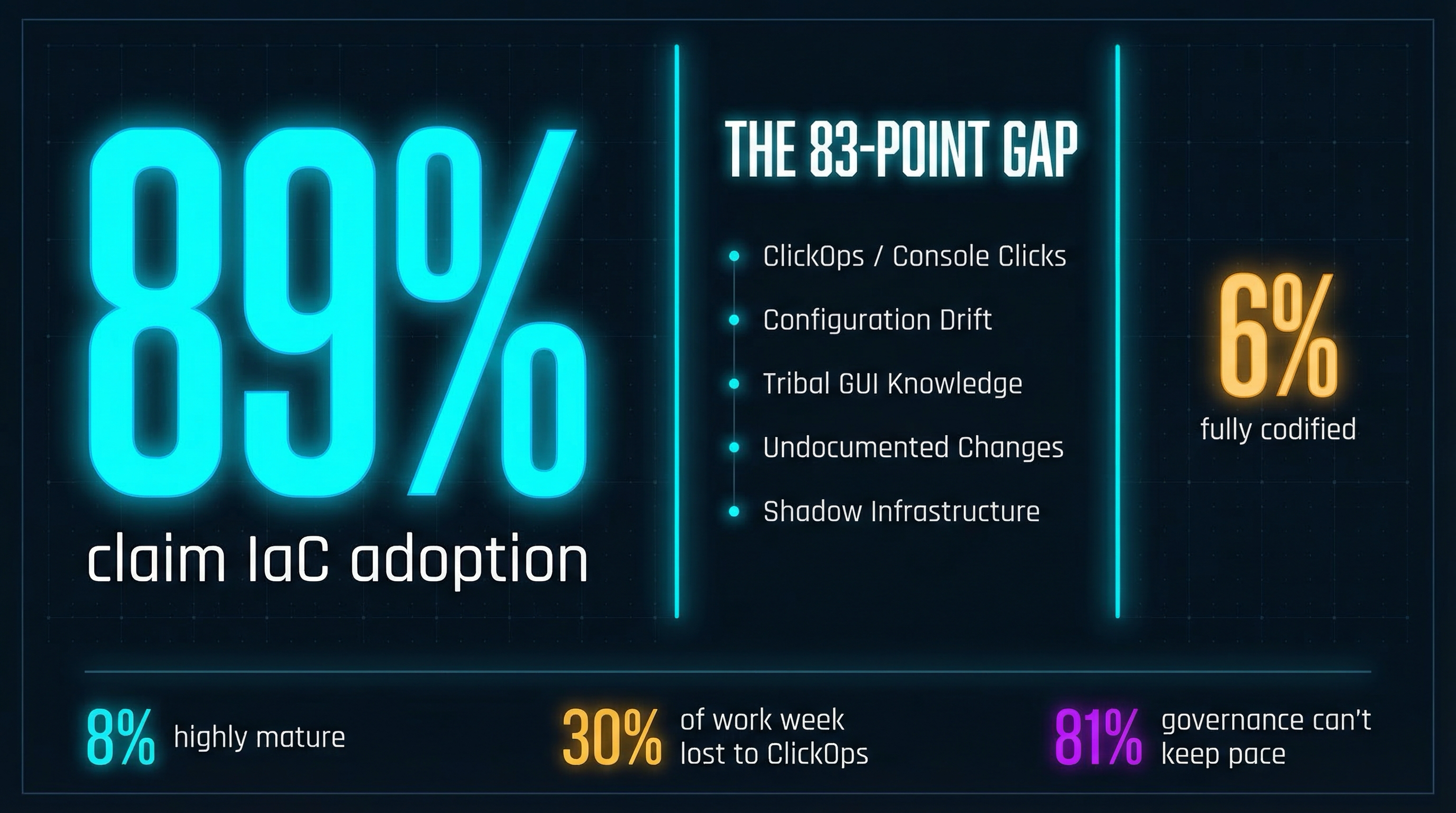
This is where the organizational story gets damning. The Firefly 2025 State of IaC Report found that 89% of organizations claim IaC adoption, but only 6% have achieved complete cloud codification. HashiCorp’s 2024 survey of 1,200 enterprises confirms it: only 8% qualify as “highly mature” in cloud practices. The CNCF’s maturity data makes the gap even starker — 0% of the least mature organizations implement GitOps, compared to 58% of the most mature.
The 83-point gap between claimed and actual IaC maturity is the story. Teams lose roughly 30% of their work week to ClickOps-related incident triage — manually replaying “quick fixes” across environments, onboarding colleagues to tribal GUI lore, chasing configuration drift that nobody tracked.
And AI is making it worse. ControlMonkey’s 2026 data shows 71% of cloud teams report GenAI is increasing their IaC volume, 63% say AI-generated infrastructure is harder to govern, and 58% have already encountered AI-introduced misconfigurations. Most critically: 81% of governance teams say manual review cannot keep pace with AI-generated change velocity. AI doesn’t replace IaC — it creates far more of it. Organizations without GitOps workflows literally cannot absorb the output.
The irony I see in banking: teams treat their AI infrastructure itself — Azure OpenAI Service, Azure ML endpoints — as ClickOps while their traditional infrastructure lives in Terraform. The same governance gap, different domain.
ArgoCD dominates GitOps tooling with 60% market share and 97% production usage among surveyed users. The enterprise case studies back the investment: Intuit went from 78% to 99.9% deployment success rates across 2,000+ microservices. Red Hat cut lead time from two weeks to two hours and change failure rate from 23% to 2.1%. The tooling exists. It works. The gap is organizational, not technical. Adopting AI IaC generation without GitOps is like buying a race car without building a road.
Policy-as-Code: The Bridge
The architecture pattern that makes AI-generated IaC safe is straightforward: AI generates Terraform → PR → terraform plan → JSON plan output → OPA/Sentinel evaluation → pass/fail gate → terraform apply. OPA evaluates the plan output, not the source code — meaning it catches what would actually be deployed, regardless of how the code was generated. Organizations implementing this pattern report a 60% reduction in production cloud misconfigurations.
The critical principle: the same policies must apply whether a human or AI wrote the change. Your validation hooks need to be author-agnostic. If your OPA policies only fire on human-authored PRs but not on AI-generated ones — or vice versa — you’ve created a governance gap that auditors will find before you do.
The Cloud Security Alliance published guidance in late 2025 arguing that “your Copilot needs a security co-pilot” — deterministic guardrails wrapping non-deterministic AI output. That framing is exactly right. The AI is the drafting tool. Policy-as-code is the review board. GitOps is the delivery mechanism. Remove any one of the three and the pattern breaks.
Why Observability Is AI’s Killer App
While code generation demands organizational maturity you may not have, observability delivers value where you already are. The structural advantages are specific:
No organizational prerequisite. You don’t need GitOps maturity to benefit from AI-assisted log analysis. Your Datadog or Grafana instance already has the data. You just need to connect an AI agent to it.
Internal data, no leakage risk. Observability data — your logs, your metrics, your traces — is proprietary. There’s no training data contamination problem. The AI is analyzing your production environment, not regurgitating Stack Overflow answers.
Immediate feedback loops. Wrong log analysis wastes a few minutes. Wrong Terraform destroys infrastructure. The cost of getting it wrong is fundamentally different.
Pattern matching is the right problem shape. LLMs excel at correlating signals across noisy, high-volume data. This is exactly what incident investigation requires — and it’s a fundamentally easier problem for current models than reasoning about infrastructure dependencies, compliance constraints, and deployment ordering.
85% of organizations already use some form of GenAI for observability, according to industry surveys. This isn’t early-adopter territory — it’s mainstream.
What I Actually Built
Here’s where this gets personal. I run Datadog’s MCP server integrated into Claude Code through PAI — Daniel Miessler’s personal AI framework, which I’ve customized into my own assistant infrastructure. The MCP server exposes get_logs, list_spans, get_trace, list_metrics, get_monitors, and list_incidents. When an incident fires, I can ask Claude Code to investigate in natural language, and it pulls live telemetry, correlates across metrics, logs, and traces, and builds a comprehensive Datadog notebook for the incident.
What impressed me most: the AI doesn’t just answer questions. It structures an entire investigation — creating notebooks with correlated data that would take 30+ minutes to assemble manually. The old way: manually hopping between dashboards, writing LogQL and PromQL queries, correlating timestamps by hand, cross-referencing deployment events with metric anomalies, then trying to build a timeline that makes sense when you present it to the team. The new way: “What caused the latency spike on the payments service in the last hour?” and watching the AI pull the thread across logs, traces, and metrics simultaneously.
The contrast with Terraform generation is stark. When Claude Code generates a Terraform module, I have to read every line, check every resource attribute, validate against our internal module library, and mentally simulate what terraform plan will produce. That’s real cognitive load. When it builds a Datadog investigation notebook, I can verify its conclusions in seconds by looking at the actual metrics it surfaced. The feedback loop is immediate and the blast radius of a bad analysis is zero — it’s a notebook, not a deployment.
The ecosystem backing this is substantial. Datadog’s Bits AI SRE hit general availability in June 2025, has run over 100,000 investigations, and claims 90% faster root cause identification. PagerDuty’s AI agent suite launched in October 2025, and their MCP server reached GA with 250+ customers in its first two months. Grafana’s Sift and LLM plugin are production-ready. The pattern is clear: every major observability vendor is building AI-assisted investigation, and MCP is becoming the connective tissue.
The trust ladder maps cleanly here. AI at Level 2-3 for observability — read-only data access, draft investigations within scoped permissions, human reviews conclusions. AI at Level 1 for IaC generation — observe and advise only, human controls every apply.
The Amplification Paradox
The 2025 DORA report delivers the most important finding in this entire space: AI amplifies what already exists. Strong teams get stronger. Weak teams get weaker. The data is specific: 21% more tasks completed, 98% more PRs merged — but organizational delivery metrics stay flat. More output, same outcomes.
The gap isn’t who can afford Datadog Enterprise or a Claude Pro subscription. It’s who already built the foundations — platform engineering, policy-as-code frameworks, internal developer platforms — that make AI tools safe and effective. Gartner predicts 40%+ of agentic AI projects will be canceled by 2027 due to escalating costs and unclear business value. Forrester’s counter-signal is even more telling: most enterprises will stick with deterministic automation through 2026 despite vendor pressure to adopt agentic features.
For regulated industries, this confirms what practitioners already know: deterministic plus AI-assisted beats fully autonomous every time. The judgment moat applies here — the value is in knowing when to trust AI output and when to override it. The skill bifurcation is real: engineers who understand what AI generates and can validate it become dramatically more productive. Engineers who trust AI output without validation become dramatically more dangerous.
What I Don’t Have Figured Out Yet
My Datadog MCP + Claude Code workflow is personal infrastructure. It’s not running under SOX audit at bank-scale production. The “comprehensive notebook” workflow is impressive for investigation, but how does it fit into formal incident management and post-incident review processes that auditors examine? I don’t have a clean answer.
The GitOps prerequisite feels binary in this post, but reality is messier. Is there a useful middle ground where organizations use AI-generated IaC in a limited scope — internal tools, non-production environments — while building GitOps maturity? Probably. I haven’t mapped it.
The review bottleneck will define the next eighteen months. 81% of governance teams say they can’t keep pace with AI-generated change velocity. Policy-as-code helps at the technical layer, but someone still needs to review the PR. When AI generates ten times more infrastructure changes, the human review step becomes the constraint — and the organizational maturity to handle that velocity is the same maturity most organizations haven’t built.
The MCP ecosystem is early. Terraform’s MCP server is read-only — it can query provider docs and workspace state but can’t execute plan or apply. The gap between “query infrastructure state” and “modify infrastructure” is exactly where the hard governance questions live. And there’s a behavioral concern Sol Rashidi’s work on brain rust makes vivid: as AI handles more of the investigation workflow, will engineers lose the muscle memory of correlating signals manually? The tool is only as valuable as the human who can evaluate whether its conclusions are correct.
Where AI Meets Your Organization
The question isn’t “should we use AI in DevOps?” It’s “where does AI meet your organization as it actually is — not as the vendor demo assumes it should be?”
If you have GitOps maturity: AI-generated IaC is a force multiplier. Embrace it with policy-as-code guardrails and human review at every apply. If you don’t: start with observability. AI-assisted log analysis and incident investigation delivers value today, without requiring organizational transformation. Then build toward GitOps — not because AI demands it, but because your infrastructure deserves it.
The winning pattern: AI reads your logs now. AI writes your Terraform when you’re ready. The cross-links tell the full story — the Trust Ladder calibrates how much autonomy AI gets by task risk, Validation Hooks provide the governance layer, and the Reference Architecture shows where observability and IaC fit in the broader stack.