
Everything Is Skill Issue
Andrej Karpathy says everything is skill issue — that when AI agents fail, the limitation is you, not the technology. He’s right. But he’s describing the solo researcher’s skill issue: calibration, prompting, orchestration. Inside an engineering department, the skill issue has two more layers he doesn’t talk about: developers who won’t adopt the tools, and management who won’t approve them. The technology works. The organization is the bottleneck.
The December Inflection
Karpathy went from writing 80% of his own code to writing essentially none of it. The shift happened in December 2024, and by March 2026 he described his state as “psychosis” — a perpetual sense of unexplored possibility where every failure feels like personal deficiency rather than technological limitation. “Code’s not even the right verb anymore,” he told the No Priors podcast. “But I have to express my will to my agents for 16 hours a day.”
The industry data backs him up. The Pragmatic Engineer survey puts weekly AI tool usage at 95% among developers, with 55% regularly using AI agents — up from near-zero eighteen months ago. A study of 129,000 GitHub projects found 15-22% already show agentic coding adoption. Claude Code PRs get accepted and merged 83.8% of the time. The top quartile of AI-adopting organizations see 2x PR throughput compared to low adopters, across 20 million pull requests analyzed by Jellyfish.
Those are industry averages. Inside a specific engineering department, the adoption curve looks nothing like the aggregate. You’re not watching a smooth line tick upward on a chart. You’re pushing against two walls simultaneously — developers who think this is a fad and leadership who thinks this is a risk — while the industry average moves without you.
The Perception Gap
Here’s where it gets uncomfortable for everyone. METR ran a randomized controlled trial with 16 experienced developers working on 246 tasks across mature open-source codebases they’d contributed to for five or more years. The developers using AI tools — Cursor Pro with Claude 3.5/3.7 Sonnet — completed tasks 19% slower than those working without AI. The critical finding: those same developers predicted AI would speed them up by 24%, and even after the slowdown, they still believed AI had made them 20% faster.
That’s a 39-point perception gap. You think you’re flying. The data says you’re walking slower than before.
But the perception gap cuts both directions. The developers who refuse AI tools have their own version of it — “I’m still productive without this.” They’re technically right, today. But the industry isn’t standing still. The Jellyfish data shows top-quartile AI adopters pulling 2x PR throughput. The gap between adopters and non-adopters widens every quarter. Refusing the tool because it didn’t work perfectly the first time you tried it is its own kind of miscalibration — confusing a bad first session with a permanent limitation.
And the enterprise numbers add a third perception gap at the organizational level. Individual developers complete 21% more tasks and merge 98% more PRs with AI assistance. But organizational delivery metrics stay flat. Seventy-five percent of engineers use AI tools. Most organizations see no measurable performance gains. The code gets written faster. The software doesn’t ship faster. Leadership sees that gap and reads it as “AI doesn’t work,” when the actual signal is “we don’t know how to measure what changed.”
The Developer Resistance
Karpathy coined “vibe coding” in early 2025, declared it passe by February 2026, and replaced it with “agentic engineering.” For him, the transition was natural — he was already orchestrating experiments, not writing application code. For a developer who’s spent a decade building expertise in a codebase, the proposition is different. You’re not offering them a better tool. You’re telling them the skill they’ve built their career on is about to be delegated.
I’ve watched this play out. The most experienced engineers — the ones you’d think would benefit most from agent delegation — are often the most resistant. They have deep mental models of how the system works, hard-won debugging instincts, and a justified confidence that they can solve problems faster than someone who doesn’t know the codebase. An agent that generates plausible-looking code without that context feels like a shortcut that skips the understanding. And they’re not entirely wrong. CodeRabbit’s analysis of 470 GitHub PRs found AI-generated code creates 1.7x more issues than human-written code. The speed is real. The quality debt is also real.
Then there’s the one-bad-experience trap. A developer asks an agent to refactor a module, the agent produces something that doesn’t account for a subtle edge case the developer knows by heart, and the developer writes off the entire category of tools. “I tried it, it doesn’t understand our codebase.” That’s a reasonable conclusion from a single data point and completely wrong as a generalization. The agent failed at a task on the jagged side of the frontier, and the developer concluded it fails at everything. That dismissal becomes permanent unless someone intervenes — and in most departments, nobody does.
The hardest part isn’t convincing developers that AI tools work. The hardest part is getting them past the identity question. If writing code is what makes you an engineer, then a tool that writes code for you feels like an existential threat. Karpathy resolved this by redefining his job — “I express my will to agents.” That reframe is easy when you’re an independent researcher. Inside a department with job descriptions, performance reviews, and promotion criteria tied to technical output, the reframe requires institutional support that usually doesn’t exist yet.
The Management Resistance
The developers who resist are at least engaging with the technology, even if they’re rejecting it. Management resistance is more structural — it happens at the approval layer, before engineers ever get their hands on the tools.
The concerns are legitimate. “What if the AI writes insecure code?” is a valid question — the 1.7x issue rate isn’t just a quality concern, it’s a security surface. “Who’s responsible when AI-generated code causes a production incident?” touches liability and audit trails that nobody designed for this. In regulated industries, AI-generated code intersects with change management processes, approval workflows, and compliance frameworks that assume a human wrote every line. The governance gap is real, and I’ve written about why trust needs to be graduated, not binary.
But valid concerns become blanket rejection when nobody owns the path forward. “We need to study this more” is the enterprise equivalent of the developer’s “I tried it and it didn’t work.” Both are ways to avoid the discomfort of changing how things are done, dressed up as reasonable caution. The difference is that management resistance blocks the entire department, not just one desk.
The ROI question is genuinely hard. The Jellyfish paradox — individual output up, organizational delivery flat — gives ammunition to skeptics. If 75% of your engineers use AI tools and your delivery metrics don’t improve, what exactly are you paying for? The honest answer is that existing metrics weren’t designed to capture what changed. Lines of code were always a bad metric; now they’re completely meaningless when an agent generates them. DORA captures deployment pipelines but misses 47% of developer time. We don’t yet have the measurement infrastructure to prove what practitioners feel in their hands. And “trust me, it works” is not an enterprise business case.
The Jagged Frontier
The reason both sides can argue convincingly is that AI doesn’t fail uniformly. It fails jaggedly. A Harvard/BCG study ran a preregistered experiment with 758 Boston Consulting Group consultants and found that tasks inside the AI capability frontier saw 40% higher quality and 25% faster completion. Tasks outside the frontier produced the opposite: accuracy dropped from 84% to 60-70%. The AI didn’t just fail to help. It actively made people worse.
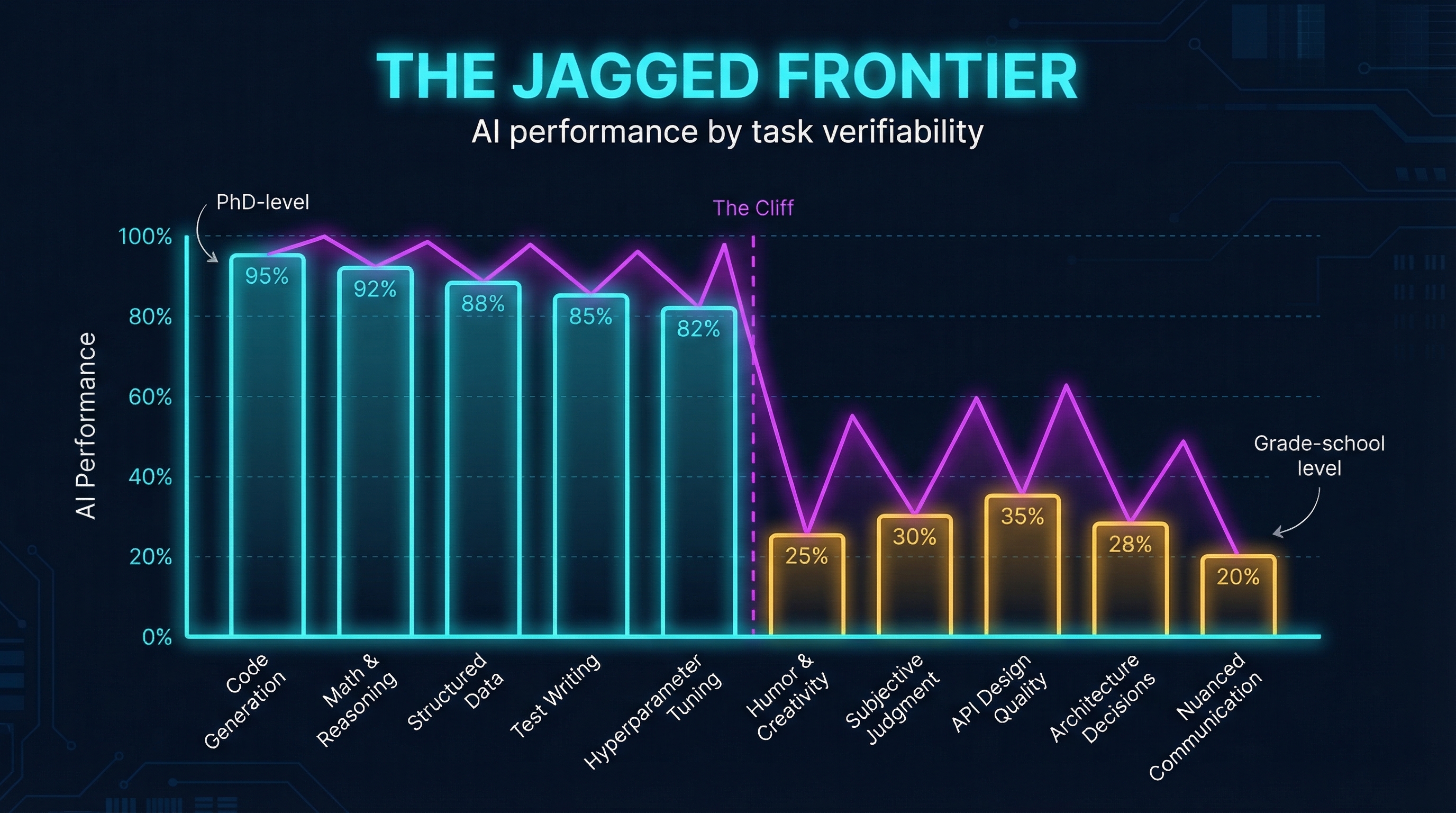
The root cause is verification asymmetry. Code has objective success criteria — it compiles or it doesn’t, tests pass or they fail. Reinforcement learning thrives on this. But architecture decisions, API design quality, and “will this be maintainable in two years?” have no unit test. RL optimizes what’s measurable, and what’s measurable is a subset of what’s valuable. Karpathy captures it perfectly: “I simultaneously feel like I’m talking to an extremely brilliant PhD student who’s been a systems programmer for their entire life and a 10-year-old.”
This jaggedness is what makes the organizational adoption problem so intractable. The developers who resist point to the failures — and they’re real. The developers who evangelize point to the successes — and they’re also real. Management sees both sides arguing with evidence and concludes nobody knows what they’re talking about. Everyone is right about their slice of the frontier. Nobody sees the full shape. And the frontier shifts with every model release, which means whatever calibration you’ve built becomes stale in months.
Where It Actually Works
If you want to see what happens when you strip away the organizational friction, look at AutoResearch.
On March 7, 2026, Karpathy open-sourced a 630-line Python script that removes humans from the ML research loop entirely. The agent modifies training code, runs a five-minute training cycle, evaluates against an objective metric, keeps or discards the change, and repeats. Karpathy pushed the script and went to sleep. By morning, the agent had run 50 experiments and found a better learning rate he’d missed. After two days: 700 experiments, 20 additive optimizations discovered, and “Time to GPT-2” dropped from 2.02 hours to 1.80 hours — an 11% efficiency gain on a repository Karpathy had tuned with twenty years of ML experience.
Tobias Lutke, Shopify’s CEO, replicated the result on internal data: 37 experiments overnight, 19% performance improvement.
The reason AutoResearch works isn’t just that the metrics are clean — training loss is an unambiguous signal. It’s that there’s no organizational resistance. One person, one repo, no approval chain. No developer arguing the agent doesn’t understand the codebase. No manager asking for an ROI projection. No compliance review of the generated code. No change advisory board. Karpathy pushed a script and went to sleep. Try that in an engineering department and count the number of gates between “push” and “sleep.” The technology delivers when you remove the organizational friction. The question is how much friction your organization requires and how much of it is load-bearing versus legacy.
The Actual Skill Issue
Karpathy is right: everything is skill issue. But the skill isn’t the same at every altitude.
For the solo researcher, the skill issue is calibration — knowing where the jagged frontier is, prompting effectively, orchestrating agents across parallel tasks. That’s the skill Karpathy has been optimizing since December. It’s real, it’s learnable, and it compounds. “The things that agents can’t do is your job now,” he says. “The things that agents can do, they can probably do better than you.”
For the engineering department, the skill issue is organizational. It’s building the case that gets management to approve the tools. It’s creating the onboarding path that gets resistant developers past the one-bad-experience trap. It’s designing the governance framework that satisfies compliance without killing the productivity gains. It’s finding or building the metrics that prove what the existing metrics can’t capture. None of this is in Karpathy’s 630-line script. All of it determines whether your team gets to use one.
The gap between Karpathy’s experience and an engineering department’s isn’t about capability. It’s about the number of humans in the decision loop. Solo researcher: one person, infinite possibility, psychosis of what to build next. Engineering department: thirty people, two approval layers, and the psychosis of getting consensus on whether to start. Karpathy asks “what should I build?” Your department is still arguing about whether to turn on the tool. That’s the skill issue nobody’s solving with better prompts. It gets solved with judgment, institutional patience, and the willingness to graduate trust one level at a time — even when the industry average is already two levels ahead.